
3편까지는 어떤 크래시가 있고 어떻게 막는지를 다뤘다.
그런데 운영 중 더 자주 부딪히는 건 이미 크래시가 난 상태에서 원인을 찾는 일이다.
특히 막막한 시나리오가 있다.
release 빌드, 사용자 단말, Crashlytics에서 받은 native 크래시 로그, 심볼은 stripped 상태.
손에 있는 건 이렇게 생긴 시그널 번호와 fault 주소, 그리고 주소만 찍힌 backtrace뿐이다.
signal 11 (SIGSEGV), code 1 (SEGV_MAPERR), fault addr 0x0
backtrace:
#00 pc 0000000000041a70 /system/lib64/libc.so
#01 pc 00000000000123bc /data/app/com.example/lib/arm64/libnative.so
#02 pc 0000000000008f10 /data/app/com.example/lib/arm64/libnative.so자바만 보던 사람은 이거 보면 막막하다.
이 상태에서 원인을 찾으려면 주소를 소스 코드 위치로 매핑해야 한다.
이번 편은 그 워크플로다.
logcat 읽기에서 시작해 심볼 매핑, 그게 안 되면 Ghidra까지 간다.
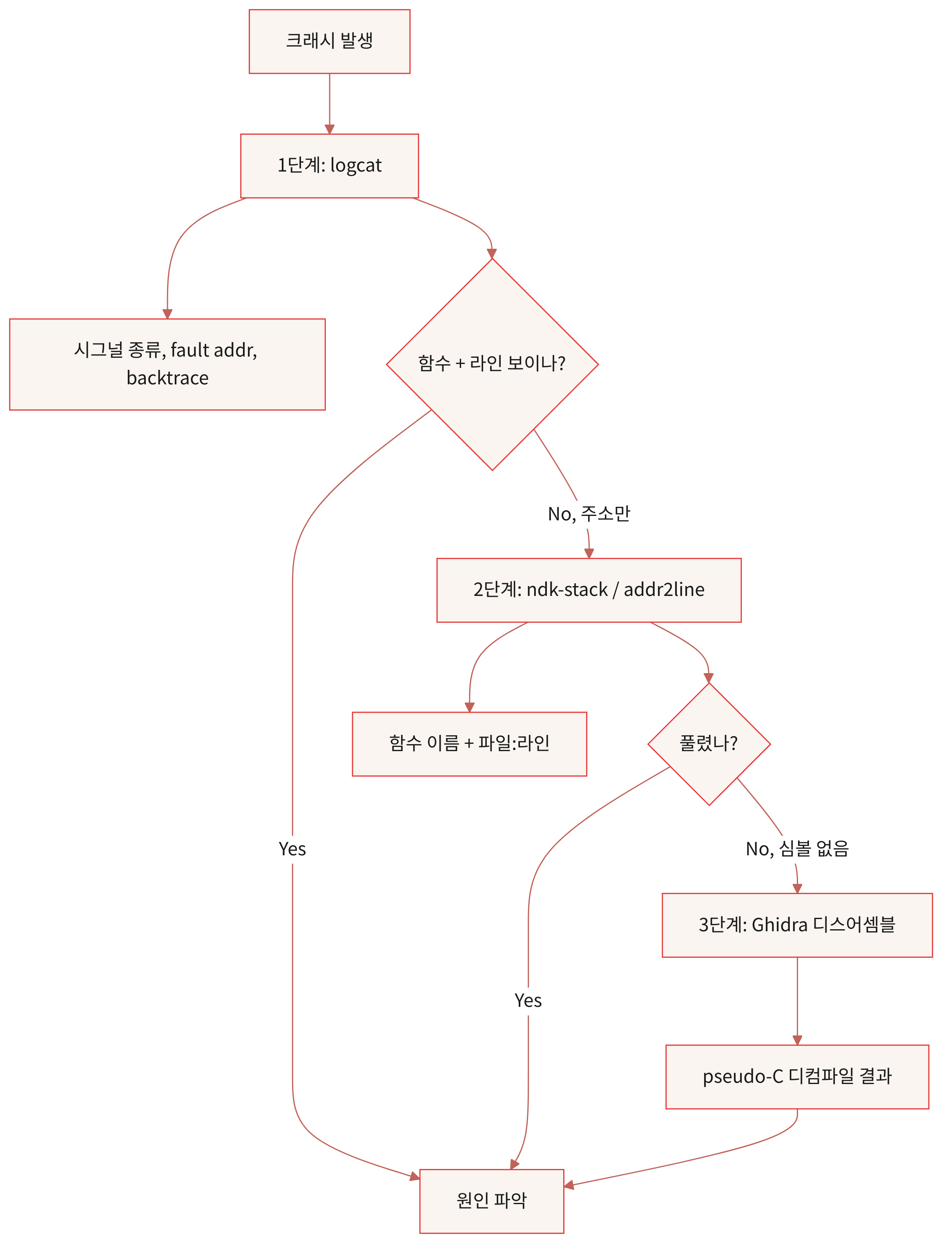
이 글은 위 흐름도의 1단계부터 3단계까지를 순서대로 따라간다.
1단계: logcat 읽기
크래시가 나면 가장 먼저 보이는 정보가 logcat임.
native 크래시의 첫 단서임.
F libc : Fatal signal 11 (SIGSEGV), code 1 (SEGV_MAPERR),
fault addr 0x0 in tid 14793 (mqt_js), pid 14724이 첫 줄에서 읽어야 할 것은 네 가지임.
- 시그널 번호와 이름을 봄. SIGSEGV면 메모리 접근 오류, SIGABRT면 의도적 종료, SIGBUS면 정렬 문제.
code값을 봄.SEGV_MAPERR는 매핑되지 않은 주소,SEGV_ACCERR는 권한 없음,BUS_ADRALN은 정렬 오류.fault addr를 봄.0x0근처면 NULL 역참조 가능성이 큼. 큰 주소면 손상된 포인터를 의심.tid와pid를 봄. 메인 스레드인지 JNI에서 만든 스레드인지 가려냄.
그다음 줄들이 backtrace임.
어떤 라이브러리의 어떤 주소에서 죽었는지 보여줌.
backtrace:
#00 pc 0000000000008f10 /data/app/com.example/lib/arm64/libnative.so
#01 pc 0000000000009124 /data/app/com.example/lib/arm64/libnative.sopc 값이 프로그램 카운터임.
그 시점에 실행 중이던 명령어의 주소임.
디버그 빌드면 함수 이름이 같이 찍히고, release 빌드는 주소만 찍힘.
backtrace는 위에서 아래로 호출 스택임.
#00이 가장 안쪽 실제 죽은 위치고, 아래로 갈수록 호출한 쪽임.
backtrace에서 내 코드를 찾으려면 줄을 세 종류로 갈라 봐야 함.
libc.so,libart.so같은 시스템 라이브러리 줄임. 시그널 처리나 JVM 런타임이라 그냥 지나감.libnative.so같은 내 native 라이브러리 줄임. 여기가 진짜 원인임.Java_com_example_...같은 함수 이름이 보이면 그게 출발점임.MainActivity.onClick같은 Java/Kotlin 호출 경로임. 내가 어디서 native를 불렀는지 알려줌.

경험상, 추적은 순서가 있음.
먼저 내 라이브러리 줄을 찾음.
그 함수가 무슨 동작이었는지 봄.
그다음 위쪽 Java 호출 경로로 맥락을 잡음.
debug 빌드에서는 함수명까지 자동 심볼화되어 libcrash.so (Java_..._triggerHeapOverflow+189)처럼 찍히는 경우가 많음.
함수 시작에서 몇 바이트 떨어졌는지(+189)까지 찍힘.
이 오프셋이 다음 단계에서 정확한 명령어를 찾는 데 쓰임.
여기서 한 가지 짚을 게 있음.
native 크래시가 나면 Android 시스템이 같은 정보를 /data/tombstones/에 tombstone 파일로 저장함.
일반 사용자 단말에서는 접근이 막혀 있음.
대신 Firebase Crashlytics 같은 서비스가 이걸 자동 수집하고 심볼화해서 보여줌.
사용자 단말 크래시는 보통 Crashlytics 대시보드로 확인함.
매핑이 깨졌거나 메모리 맵까지 봐야 하는 케이스에서만 tombstone 원본을 직접 엶.(가능하면)
2단계: 심볼 매핑 (addr2line, ndk-stack)
1단계에서 주소만 손에 쥐었으면, 이제 그 주소를 소스 코드 위치로 매핑할 차례임.
먼저 디버그 심볼이 어디 있는지부터 알아야 함.
release 빌드의 .so는 보통 stripped 상태라 함수 이름도 라인 정보도 없음.
매핑하려면 strip 전의 unstripped 라이브러리가 따로 필요함.
AGP(Android Gradle Plugin)로 빌드했다면 이 경로에 unstripped .so가 있음.
<프로젝트>/build/intermediates/cxx/<build-type>/<hash>/obj/<abi>/이 파일은 빌드한 사람의 머신에 보관되어 있어야 함.
빌드 산출물을 안 보관해두면 나중에 같은 빌드를 재현 못 함.
이게 가장 흔한 실수임.
그래서 빌드마다 unstripped .so를 별도 디렉토리에 보관해두는 게 정석임.
심볼이 준비됐으면 ndk-stack이 가장 간단함.
logcat 출력을 받아 심볼화된 backtrace로 바꿔주는 도구임.
NDK에 기본 포함되어 있음.
adb logcat | ndk-stack -sym ./obj/arm64-v8a파일로 저장한 뒤 처리할 수도 있음.
adb logcat > crash.txt
ndk-stack -sym ./obj/arm64-v8a -dump crash.txt결과로 함수 이름과 파일:라인이 같이 찍힘.
#00 pc 0000000000008f10 /data/app/.../libnative.so
process_data
/Users/me/project/src/processor.cpp:142특정 주소 하나만 매핑하고 싶으면 addr2line을 씀.
$NDK/toolchains/llvm/prebuilt/linux-x86_64/bin/llvm-addr2line \
-e ./obj/arm64-v8a/libnative.so \
-f -C 0x8f10-e는 매핑 대상 라이브러리, -f는 함수 이름까지 출력, -C는 C++ 심볼 demangle 옵션임.
backtrace의 pc 값은 보통 이미 라이브러리 내부 상대 오프셋으로 찍혀 있음.
logcat이나 tombstone이 라이브러리 시작 주소를 빼서 표시하기 때문임.
그래서 그 값을 그대로 addr2line에 넘기면 됨.
대부분의 native 크래시는 ndk-stack 한 번이면 함수와 라인까지 나옴.
함수 이름이 보이면 그 함수 코드를 보며 어떤 입력이 어떤 사고를 만들었는지 추적하면 됨.
3단계: 도구가 안 풀 때 Ghidra
다음 상황에서는 2단계 도구가 한계에 부딪힘.
여기서 막히기 쉬움.
- unstripped 라이브러리를 분실한 경우. 빌드 산출물을 안 보관해 매핑할 심볼이 없음.
- 외부 prebuilt 라이브러리에서 죽은 경우. 회사 SDK나 third-party 라이브러리는 우리 빌드 산출물이 아니라 심볼 자체가 없음.
- 이미 release로 배포된 SDK라 어디서 죽는지 봐야 하는데 빌드 환경이 없는 경우.
- inline이나 LTO 최적화가 적용된 경우. 함수가 원본 형태로 존재하지 않아 addr2line이 최선의 추측만 함.
이런 경우엔 디스어셈블 단계로 내려가야 함.
그게 Ghidra 영역.
Ghidra는 디스어셈블러이자 디컴파일러.
stripped된 .so를 디스어셈블하고 pseudo-C 코드로 디컴파일해줌.
기계어를 읽을 수 있는 C 비슷한 언어로 옮겨주는 번역기에 가까움.
완벽한 번역은 아니지만 코드 구조는 드러남.
Ghidra 기본 워크플로는 이 순서임.
각 단계의 메뉴 위치를 그대로 따라가면 됨.
- APK에서
lib/arm64-v8a/libnative.so를 추출함. APK는 ZIP이라 unzip으로 풀림. - Ghidra를 실행하고
File → New Project로 프로젝트를 생성함. File → Import File로.so를 로드함. Format과 Language가 자동 감지됐는지 확인함.- 프로젝트 창에서 import한 파일을 더블 클릭하면 Code Browser가 열리고, Auto-analyze를 진행할지 묻는 프롬프트가 뜸. 진행함.
- 크래시 위치로 점프함. 점프 방법은 아래에서 따로 다룸.
- 우측 Decompile 패널에서 해당 함수의 디컴파일 결과를 봄.
크래시 위치로 점프할 때 한 가지 함정이 있음.
backtrace의 pc 값을 Ghidra Go To에 그대로 넣으면 보통 못 찾음.
pc는 실행 시점의 메모리 주소인데 Ghidra가 보는 건 .so 파일 안의 주소라 다르기 때문임.
그래서 함수 시작 주소에 오프셋을 더하는 방식을 씀.
backtrace가 이렇게 찍혔다고 하면:
#06 pc 0000000000003480 libcrash.so
(Java_com_example_..._triggerHeapOverflow+189)다음 순서로 점프함.
- Symbol Tree에서
Java_..._triggerHeapOverflow함수를 찾아 더블 클릭함. - Listing 패널이 그 함수 시작 위치로 점프함. 함수 시작 주소를 확인함. 예를 들어
0x10033c0임. - backtrace의 오프셋
+189는 십진수임. 16진수로 바꾸면0xBD임. - 함수 시작 주소에 오프셋을 더함.
0x10033c0 + 0xBD = 0x100347D임. Navigation → Go To...메뉴, 단축키G로 그 주소를 입력함.
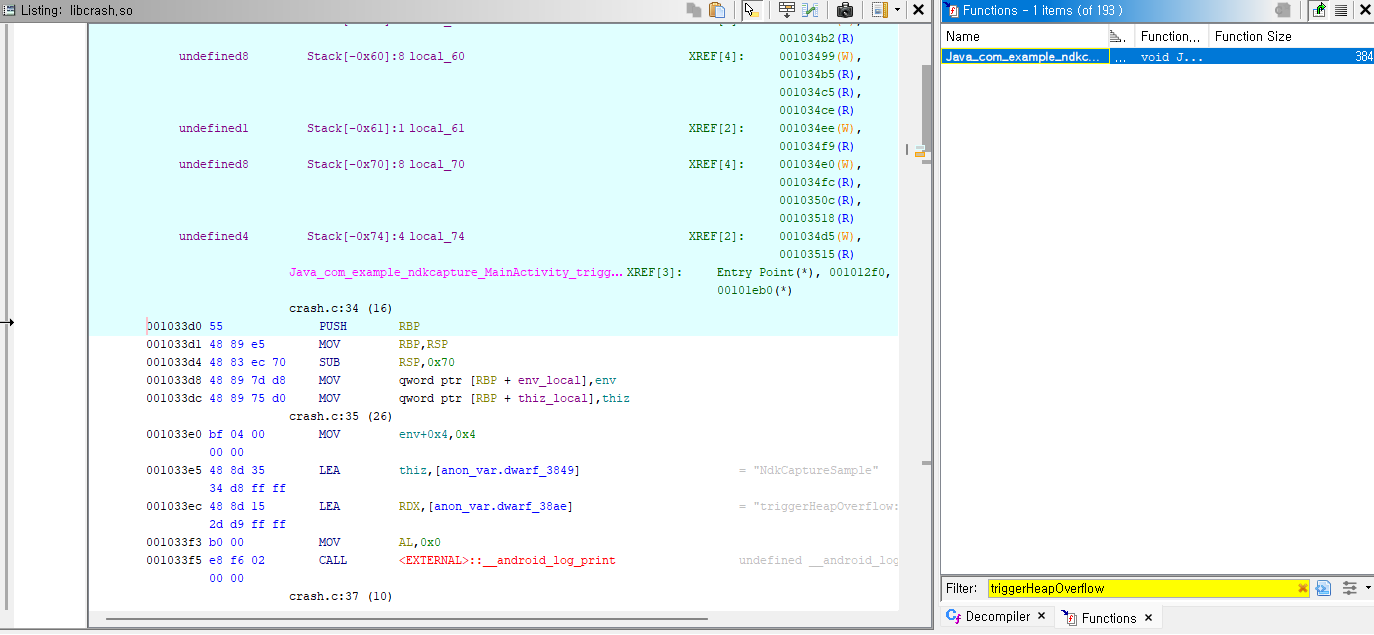
이렇게 점프하면 backtrace에 찍힌 그 명령어를 정확히 볼 수 있음.
함수가 짧으면 오프셋 없이 함수 전체 디컴파일로도 추정됨.
큰 함수에서는 정확한 명령어 위치가 중요해짐.
디컴파일 결과는 이렇게 나옴.
void FUN_00008f00(int *param_1) {
int local_8;
local_8 = *param_1; // 0x8f10. param_1이 NULL이면 여기서 SIGSEGV
process_value(local_8);
}함수 이름은 주소 기반 자동 이름(FUN_00008f00)으로 나오지만 코드 구조는 보임.
어떤 변수가 어디서 왔는지, 어떤 함수를 호출하는지, 왜 그 주소에서 죽었는지 추적 가능함.
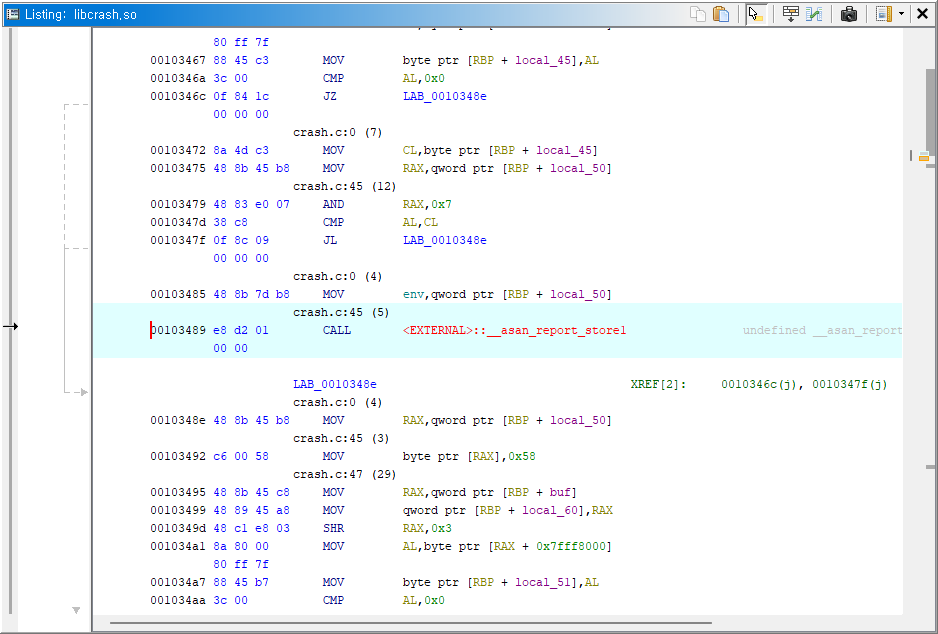
ASan이 켜진 빌드에서는 디스어셈블 결과에 원본 코드에 없던 코드가 같이 보임.
메모리 쓰기 한 줄을 분석하려고 어셈블리를 보면, 그 쓰기 명령어 앞에 shadow memory 조회와 안전 검사가 끼어 있음.
3편에서 설명한 "컴파일러가 모든 메모리 접근에 검사 코드를 삽입한다"는 ASan 원리가 어셈블리 레벨에서 드러나는 모습임.
JNI 함수에서 죽었다면 추적이 더 쉬워짐.
native 라이브러리의 JNI 함수는 Java_com_example_MyClass_processData처럼 Java 클래스명과 메서드명 기반으로 자동 이름이 붙음.
이 이름이 stripped 후에도 남음.
JNI 호환 때문임.
System.loadLibrary() 이후 Java가 native 메서드를 호출하려면 런타임에 함수 이름으로 찾아 동적 링크해야 함.
그래서 컴파일러가 JNI 함수를 export 심볼로 박아두고, strip 도구도 이 export 심볼은 안 건드림.
결국 stripped 라이브러리에서도 JNI 함수 이름은 그대로 남음.
Ghidra 함수 목록에서 바로 찾을 수 있음.
이 단계까지 오면 심볼 없는 release 빌드에서도 원인 추적이 됨.
다만 시간이 더 듦.
addr2line이 30초라면 Ghidra는 30분 단위임.
마무리 메모
이번 편에서 알아갈 것은 CLAUDE한테 '해줘' 라고 하지말고. 'Ghidra로 분석 해줘' 라고 하면 된다는 것만 알고가자.
일반적인 개발자가 이렇게 까지 분석하는 것은 어렵다.
나는 보안 개발을 하다보니 리버싱 엔지니어링 할 일이 많고 ghidra가 익숙해서 이렇게 한다.
보통 이렇게 안할 수도 있다.
이번 편은 내 노하우에 가깝다고 할 수 있다.
시리즈를 마치며
시리즈에서 다룬 말은 결국 Java/Kotlin이 알아서 해주던 것을 native에서는 내가 의식해야 한다는 것이다.
Reference 정리는 GC가 하던 일이고, 메모리 안전은 JVM이 하던 일이고, 크래시 정보는 stack trace가 다 찍어주던 것이다.
생각해보면 NDK가 어렵다는 말은 어느 정도 오해다.
나도 앱 개발에 더 익숙하고, 자바/코틀린이 좋으며, C/C++ 잘 모르고, NDK 개발도 아직 잘 못한다.
근데 NDK를 다뤄보면 그냥 자바/코틀린에 익숙한 요즘 개발자가 나약한거 아닌가 생각도 든다.
그래서 나오는 native 크래시들을 보면 내게 이러는 것 같다.

참고 자료
- ndk-stack (Android NDK 공식 문서) - https://developer.android.com/ndk/guides/ndk-stack
- Ghidra (공식 사이트) - https://ghidra-sre.org
'모바일' 카테고리의 다른 글
| Android NDK 입문 (3) - AddressSanitizer, 스택 카나리 알고 네이티브 크래시 미리 막기 (0) | 2026.05.24 |
|---|---|
| Android NDK 입문 (2) - SIGSEGV, SIGABRT, SIGBUS 네이티브 크래시 시그널 정리 (0) | 2026.05.23 |
| Android NDK 입문 (1) - NDK를 왜 쓰는가, JNI와 네이티브 개발 기초 (0) | 2026.05.23 |
| Google Play 데이터 보안: AdMob 사용 시 "기기 또는 기타 ID 선언되지 않음" 경고 해결 (0) | 2026.05.23 |
| Android 개발자 인증 정리 - Play Console 등록 가이드 (0) | 2026.04.19 |