
패턴 56개를 만들었다. 인젝션 탐지 13개, 시크릿 탐지 24개, 커맨드 인젝션 6개, 데이터 유출 6개, PII 탐지 7개.
근데 이게 진짜 잡히는 건지 확인을 해봐야 했다. 패턴을 만드는 것과 패턴이 실제 공격을 막는 것은 다른 문제다. 모바일 보안 일을 하면서 매번 겪었던 일이기도 하다. TouchEn mVaccine에서 루팅 탐지 시그니처를 추가하면, 내부 레드팀이 바로 우회를 시도한다. Magisk Hide가 나오면 새 시그니처를 넣고, 패키지명 랜덤화가 나오면 또 대응하고. 방어자가 직접 공격자가 되어보지 않으면 진짜 구멍을 못 찾는다.
감사는 두 가지 축으로 진행했다. QA 엔지니어 관점에서는 정상 입력이 오탐 없이 통과하는지, 알려진 공격이 정확히 걸리는지, 엣지 케이스(빈 입력, 초대형 입력, 유니코드 입력)에서 크래시가 안 나는지 확인했다. 레드팀 관점에서는 패턴을 피해가는 방법을 최대한 찾았다. 인코딩 우회, 문자 대체, ReDoS, 점수 조작 같은 것들.
총 5회 감사를 돌렸다. 매 개발 주차마다 한 번씩. 결과적으로 CRITICAL 2건, HIGH 12건을 찾았다.
호모글리프 — 눈에는 같은데 컴퓨터는 다르게 읽는 문자
첫 번째로 시도한 건 유니코드 호모글리프(homoglyph) 우회다.
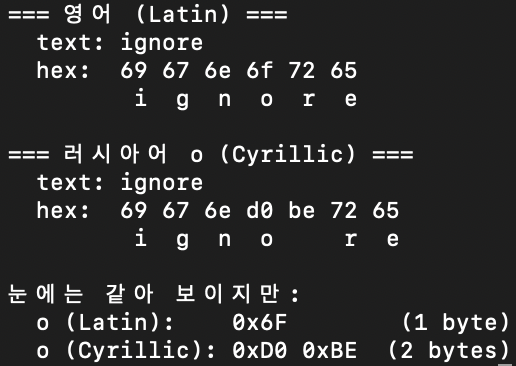
호모글리프는 시각적으로 동일하지만 유니코드 코드포인트가 다른 문자다. 영어 소문자 o(U+006F)와 러시아어(Cyrillic) о(U+043E)는 사람 눈에는 구분이 안 된다. 에디터에서 나란히 놓아도 똑같이 보인다. 하지만 바이트 수준에서는 완전히 다른 문자다.
| 원래 문자 | 호모글리프 | 코드포인트 | 시각적 차이 |
|---|---|---|---|
o (Latin) |
о (Cyrillic) |
U+043E | 없음 |
i (Latin) |
і (Cyrillic) |
U+0456 | 없음 |
A (Latin) |
Α (Greek) |
U+0391 | 없음 |
ignore previous instructions라는 인젝션 패턴이 있다고 하자. 여기서 o 하나를 Cyrillic о로 바꾸면:
"ign\u043ere all previous instructions" → INJ-001 우회 성공regex 엔진 입장에서 o와 о는 아예 다른 문자다. 패턴에 매치가 안 된다. 이걸 56개 패턴 전부에 시도해봤다. 어떤 패턴이든 키워드의 글자 하나만 호모글리프로 바꾸면 뚫렸다. 전멸.
피싱 사이트 URL에 Cyrillic을 섞는 것과 같은 원리다.
대응: normalizeText()
모든 패턴 매칭 전에 텍스트를 정규화하는 전처리 함수를 추가했다. engine.ts의 normalizeText()다.
const HOMOGLYPH_MAP: Record<string, string> = {
'\u043E': 'o', '\u0456': 'i', '\u0443': 'y',
'\u0410': 'A', '\u0412': 'B', '\u0421': 'C',
'\u0415': 'E', '\u041D': 'H', '\u041A': 'K',
// ... Cyrillic, Greek, Cherokee → ASCII 매핑 43개
};
function normalizeText(text: string): string {
// 1. invisible character 제거
let normalized = text.replace(
/[\u200B-\u200F\u2060-\u206F\u00AD\uFEFF\u034F]/g, ''
);
// 2. 호모글리프 → ASCII 치환
normalized = normalized.replace(
/[\u0391-\u03C9\u0400-\u04FF\u13A0-\u13F4]/g,
(ch) => HOMOGLYPH_MAP[ch] ?? ch
);
// 3. URL 인코딩 디코딩
try { normalized = decodeURIComponent(normalized); } catch {
normalized = normalized.replace(/%([0-9A-Fa-f]{2})/g,
(_, hex) => String.fromCharCode(parseInt(hex, 16)));
}
// 4. HTML 엔티티 디코딩
normalized = normalized.replace(/&#(\d+);/g,
(_, n) => String.fromCharCode(Number(n)));
return normalized;
}처음에는 NFKD(Unicode Normalization Form KD)를 쓸까 했다. NFKD는 유니코드 호환 분해를 해서 합자(ligature)나 호환 형태를 기본 형태로 바꿔준다. 그런데 NFKD를 적용하면 한국어 자모가 분해된다. CJK 문자에 영향이 가는 건 다국어 지원 측면에서 문제가 있었다. 그래서 직접 매핑 테이블을 만들었다. 매핑이 43개로 많지 않고, 어떤 문자가 어떻게 바뀌는지 한눈에 보이니까 유지보수도 낫다.
제로폭 문자 — 보이지도 않는데 패턴이 깨진다
호모글리프보다 더 교활한 우회가 제로폭 문자(zero-width character) 삽입이다.
zero-width space(U+200B), zero-width joiner(U+200D), soft hyphen(U+00AD) 같은 문자를 키워드 중간에 삽입하면 텍스트가 시각적으로 동일하지만 regex가 매치하지 못한다.
| 문자 | 코드포인트 | 이름 |
|---|---|---|
| (보이지 않음) | U+200B | Zero-width space |
| (보이지 않음) | U+200D | Zero-width joiner |
| (보이지 않음) | U+00AD | Soft hyphen |
| (보이지 않음) | U+200C | Zero-width non-joiner |
"ig\u200Bnore previous instructions" → INJ-001 우회
"<sys\u200Btem>" → INJ-004 우회호모글리프는 그래도 hex dump를 뜨면 다른 문자로 보이기라도 한다. 제로폭 문자는 아예 보이지 않는다. 에디터에서 열어도, 터미널에서 출력해도 차이를 알 수 없다. 유니코드 검사기를 돌리거나 hex dump를 떠봐야 존재를 알 수 있다.
이것도 56개 패턴 전부에 적용된다. AWS 키 패턴 AKIA도 AK\u200BIA로 쓰면 SEC-001이 안 걸린다.
대응은 normalizeText() 안에 이미 들어가 있다. 위 코드의 1번 단계, invisible character 제거가 그것이다.
text.replace(/[\u200B-\u200F\u2060-\u206F\u00AD\uFEFF\u034F]/g, '');이 한 줄이 56개 패턴 전체의 제로폭 문자 우회를 막는다.
호모글리프 정규화가 러시아어 패턴을 깨뜨렸다
호모글리프 문제를 고쳤더니 새로운 문제가 생겼다. 방어를 강화했더니 다른 방어가 깨진 것이다.
mcp-fence에는 다국어 인젝션 패턴이 있다. INJ-012에 러시아어 인젝션이 포함되어 있다.
"игнорируй предыдущие инструкции" (이전 지시를 무시하라)이 텍스트에는 Cyrillic 문자가 들어있다. 그런데 normalizeText()가 Cyrillic 문자를 전부 Latin으로 바꿔버린다. и가 n으로, о가 o로 바뀌면서 "nгнорnруй" 같은 괴상한 문자열이 된다. 러시아어 패턴에 당연히 매치가 안 된다.
호모글리프 우회를 막으려고 넣은 정규화가 정상적인 러시아어 인젝션 탐지를 파괴한 것이다. 이건 전형적인 보안의 딜레마다.
대응: dual-pass 매칭
해결은 인젝션 패턴을 두 번 돌리는 것이다. 정규화 전 텍스트에 한 번, 정규화 후 텍스트에 한 번.
// 1. 정규화된 텍스트에서 패턴 매칭 (호모글리프 우회 방어)
text = normalizeText(text);
for (const pattern of patterns) {
const finding = matchPattern(pattern, text);
if (finding) findings.push(finding);
}
// 2. 정규화 전 텍스트에서 한 번 더 (다국어 패턴 보호)
// invisible char만 제거하고 호모글리프 치환은 안 함
const strippedOriginal = originalText.replace(
/[\u200B-\u200F\u2060-\u206F\u00AD\uFEFF\u034F]/g, ''
);
if (preNormText !== text) {
const existingRuleIds = new Set(findings.map(f => f.ruleId));
for (const pattern of patterns) {
if (existingRuleIds.has(pattern.id)) continue; // 중복 제거
const finding = matchPattern(pattern, preNormText);
if (finding) findings.push(finding);
}
}정규화 전 텍스트에서는 invisible character만 제거한다. 호모글리프 치환은 안 한다. 이렇게 하면 러시아어 игнорируй가 그대로 남아서 INJ-012에 매치된다. 정규화 후 텍스트에서는 호모글리프가 치환되니까 ignоre(Cyrillic o) 같은 우회도 잡힌다.
패턴을 두 번 돌려도 1ms 미만이다. regex 매칭 자체가 가벼운 연산이고, 두 번째 pass에서는 이미 걸린 패턴을 건너뛰니까 실제 추가 비용은 더 적다.
다만 이건 근본적 해결이 아니다. 다국어 패턴이 늘어날수록 이런 충돌이 더 생길 수 있다. v2.0에서 임베딩 기반 탐지로 전환하면 문자 수준이 아니라 의미 수준에서 잡으니까 이 문제가 구조적으로 사라진다.
head + tail 스캐닝 — 중간에 인젝션을 숨기면?
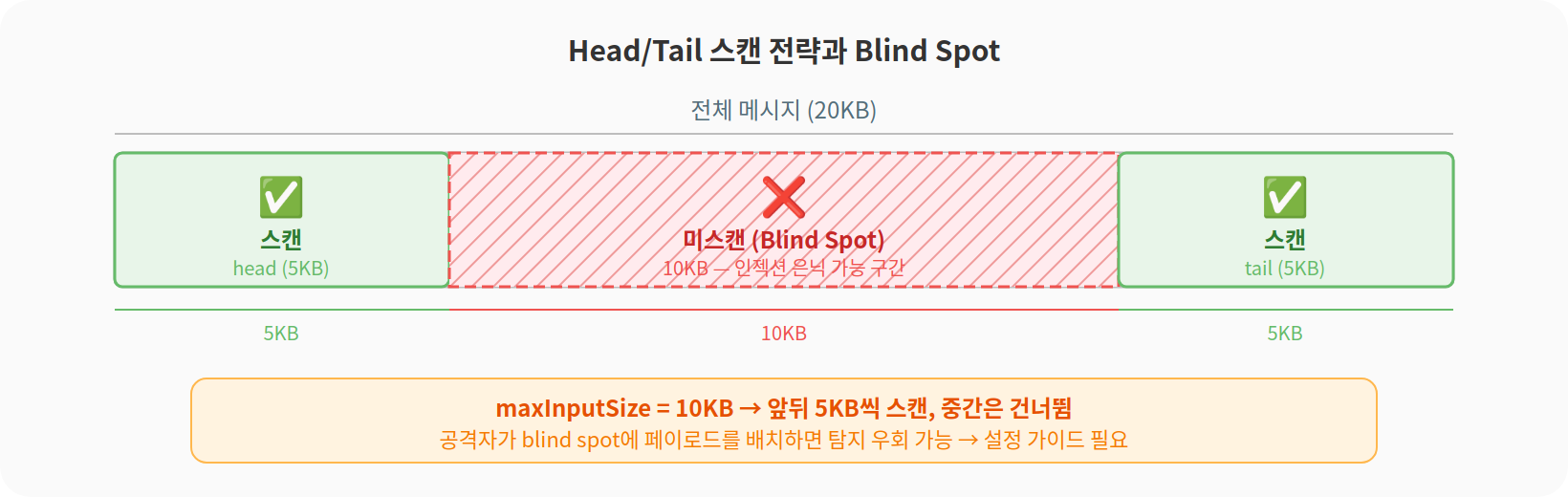
mcp-fence에는 maxInputSize 설정이 있다. 기본값 10KB. 메시지가 이것보다 크면 잘라서 스캔한다. 100KB짜리 메시지를 통째로 regex에 돌리면 ReDoS 위험이 커지니까.
처음에는 앞부분만 잘랐다. text.slice(0, maxInputSize). 하지만 공격자가 정상 텍스트 10KB를 앞에 넣고 맨 뒤에 페이로드를 숨기면 못 잡는다.
대응: 앞 절반 + 뒤 절반
let tailText = '';
if (text.length > this.config.maxInputSize) {
const halfSize = Math.floor(this.config.maxInputSize / 2);
tailText = text.slice(-halfSize);
text = text.slice(0, halfSize);
}tail 부분은 별도로 스캔하고, 중복 결과는 ruleId로 제거한다. 시크릿 패턴도 같은 방식으로 head + tail 스캔을 적용했다.
가운데는 여전히 blind spot이다. 트레이드오프라는 걸 알고 선택한 거다. maxInputSize를 키우면 커버리지는 올라가지만 ReDoS 위험이 같이 올라간다.
ReDoS — 보안 도구 자체가 DoS 벡터
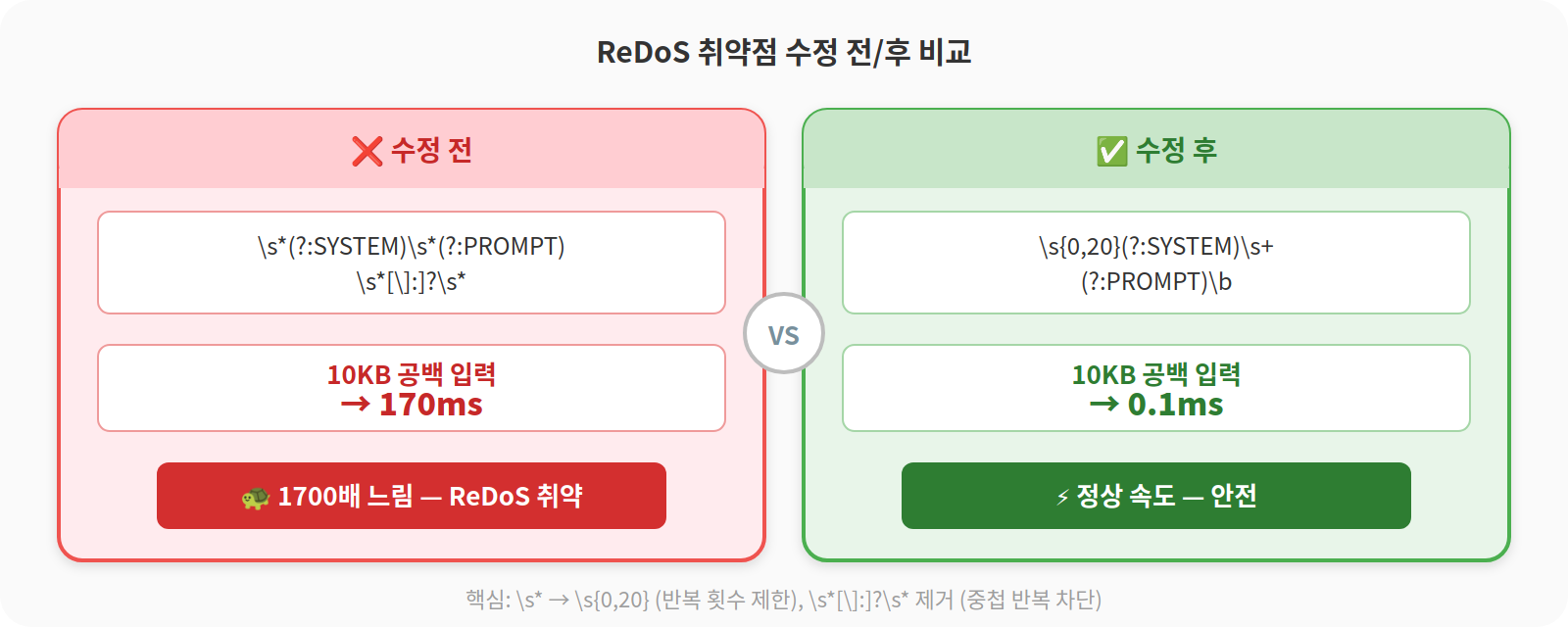
patterns.ts의 25개 패턴(인젝션 13 + 커맨드 6 + 유출 6) 전부에 대해 ReDoS 테스트를 돌렸다. 각 패턴에 10KB 공백, 10KB 반복 문자, 알려진 ReDoS 페이로드를 넣었다.
INJ-003에서 문제가 터졌다. 10KB 공백 입력에 170ms. 패턴당 예산으로 잡아둔 5ms의 34배다.
// INJ-003: system_prompt_injection (취약한 버전)
/\[?\s*(?:SYSTEM|ADMIN|ASSISTANT)\s*(?:PROMPT|MESSAGE|INSTRUCTION|NOTE)\s*[\]:]?\s*/i문제는 \s*가 4개 연속으로 있는 것이다. 각 \s*가 0개 이상의 공백을 매치할 수 있고, 사이에 있는 alternation 그룹이 빈 문자열을 매치하지 못해서 regex 엔진이 지수적으로 탐색한다. 10,240개의 공백을 \s* 4개에 배분하는 경우의 수는 폭발한다.
공격 시나리오를 생각해보면 심각하다. 공격자가 MCP 메시지에 10KB 공백을 넣는다. mcp-fence가 스캔하면서 170ms 동안 이벤트 루프가 멈춘다. Node.js는 싱글 스레드니까 그 동안 다른 요청을 처리 못 한다. 보안 도구 자체가 DoS 벡터가 되는 것이다.
수정
가운데 \s*를 \s+로, 앞쪽 \s*를 \s{0,20}(최대 20개)으로 바꿨다.
// 수정 후
/\[?\s{0,20}(?:SYSTEM|ADMIN|ASSISTANT)\s+(?:PROMPT|MESSAGE|INSTRUCTION|NOTE)\b/i\s+는 최소 1개 공백을 요구한다. 빈 매치 가능성이 사라지면서 백트래킹이 사라진다. 수정 후 같은 입력에서 0.1ms 미만. 1700배 개선.
시크릿 패턴에서도 ReDoS가 2건 나왔다.
SEC-004(Azure 연결 문자열)에서는 = 문자가 리터럴 =와 문자 클래스 [A-Za-z0-9+/=] 양쪽에 있었다. AccountKey= 뒤에 5000개의 =를 넣으면 regex 엔진이 각 =를 어느 쪽에 배분할지 탐색한다. 90ms 걸렸다. =를 문자 클래스에서 빼고 [A-Za-z0-9+/]{20,}={0,3}으로 분리해서 해결했다.
SEC-014(OpenAI 키)에서는 \b word boundary와 하이픈 반복의 조합이 문제였다. sk- 뒤에 5000개의 -에 !를 붙이면 \b에서 백트래킹이 발생한다. \b를 제거하고 lookahead로 대체해서 해결했다.
툴 이름 null byte 우회 — 정책 엔진의 구멍
이건 W5 감사에서 발견한 건데, CRITICAL로 분류했다.
정책 엔진에서 도구 이름으로 allow/deny를 판단한다. exec_cmd를 deny로 설정했다고 하자.
policy:
rules:
- tool: "exec_cmd"
action: "deny"공격자가 도구 이름에 null byte, 공백, 대소문자 변형, invisible 문자를 넣으면?
"exec_cmd" → deny (정상)
"EXEC_CMD" → allow (대소문자 미처리)
"exec_cmd\u0000" → allow (null byte 추가)
" exec_cmd " → allow (공백 추가)
"exec\u200Bcmd" → allow (제로폭 문자 삽입)정책 엔진이 도구 이름을 정규화하지 않고 문자열 그대로 비교하고 있었다. 탐지 엔진에는 normalizeText()를 넣어놓고 정책 엔진에는 안 넣었던 것이다. 이건 설계 결함에 가깝다.
수정
normalizeToolName() 함수를 local.ts에 추가했다.
function normalizeToolName(name: string): string {
return name
.replace(/[\u200B-\u200F\u2060-\u206F\u00AD\uFEFF\u034F\x00]/g, '')
.trim()
.toLowerCase();
}정책 규칙의 tool 이름과 실제 들어온 tool 이름 양쪽에 이 정규화를 적용한다. matchesToolPattern() 함수 안에서 비교 전에 양쪽 다 normalizeToolName()을 거친다.
실무에서 이런 류의 버그가 위험한 이유가 있다. 정책 엔진은 "이 도구를 차단합니다"라는 명시적 약속이다. 이 약속이 문자 하나로 깨진다는 건, 사용자가 자기 정책이 동작한다고 믿는 상태에서 실제로는 안 동작하는 것이다. 오탐(false positive)보다 미탐(false negative)이 더 위험한 전형적 사례.
감사 결과
5회 감사에서 총 1,426개 테스트를 작성했다. 주차별로 보면 W2에서 413개, W3에서 291개, W4에서 112개, W5에서 148개, W6/W7에서 462개. W2가 가장 많았는데, 기본 구조를 전부 깨본 시점이라 그렇다. W4에서 줄어든 건 이때 구조가 안정되기 시작한 거고, W6/W7에서 다시 올라간 건 호모글리프 정규화가 다국어 패턴을 깨뜨리는 문제 같은 2차 효과를 잡아내면서다.
CRITICAL 2건은 INJ-003 ReDoS(보안 도구 자체를 멈출 수 있음)와 툴 이름 null byte 우회(정책 차단을 무력화). 둘 다 즉시 수정했다.
HIGH 12건은 호모글리프 우회, 제로폭 문자 우회, SEC-004/014 ReDoS, 호모글리프 정규화가 러시아어 패턴을 파괴하는 문제, 사용자 정의 regex ReDoS 등이었다. 역시 전부 즉시 수정.
즉시 수정한 기준은 세 가지다. 공격자가 쉽게 악용 가능하거나, 프록시 가용성 자체를 위협하거나, 수정 비용이 낮은 것. 이 세 가지 중 하나라도 해당하면 바로 고쳤다.
로드맵에 남긴 것도 있다. 동의어/패러프레이즈 우회는 regex의 구조적 한계다. cross-message 공격(개별 메시지는 깨끗한데 합치면 공격), 점수 알고리즘 예측(공격자가 패턴을 알면 threshold 아래로 점수를 조정) 같은 것도 아키텍처 변경이 필요해서 로드맵에 넣었다.
깨보지 않았으면 몰랐을 것들
regex 기반 탐지의 한계는 명확하다. 동의어 우회, 다국어 완전 커버리지, cross-message 공격, 점수 알고리즘 예측 — 이런 건 regex로 원천적으로 막을 수 없다.
하지만 직접 깨봤기 때문에 "뭘 못 잡는지"를 안다. 유니코드 정규화, invisible character 제거, head+tail 스캐닝, dual-pass 매칭 — 이런 대응은 감사를 하지 않았으면 생각도 못 했을 것이다. 특히 호모글리프 정규화가 러시아어 패턴을 깨뜨리는 문제는 코드를 읽어서는 알 수 없다. 실제로 공격을 시도해봐야 나온다.
보안 도구를 만드는 사람은 공격자보다 먼저, 더 많이, 자기 도구를 깨봐야 한다.
다음 편에서는 인젝션이 없어도 막아야 하는 요청이 있다는 걸 다룬다. 콘텐츠가 깨끗해도 도구 자체가 위험할 수 있는 이유, 그리고 탐지와 기록을 분리해야 하는 이유.
'개발기' 카테고리의 다른 글
| MCP AI 에이전트 보안 프록시 개발기 (5) — 시크릿 마스킹과 HMAC 해시 체인 (0) | 2026.04.14 |
|---|---|
| MCP AI 에이전트 보안 프록시 개발기 (4) — YAML 정책 엔진과 SARIF 감사 로깅 (0) | 2026.04.14 |
| MCP AI 에이전트 보안 프록시 개발기 (2) — regex로 프롬프트 인젝션 탐지하기 (1) | 2026.04.14 |
| MCP AI 에이전트 보안 프록시 개발기 (1) — MCP 서버 응답은 검증 없이 AI에 전달된다 (0) | 2026.04.14 |
| NAVER WORKS CLI + MCP 서버 개발기 (2) — MCP 서버 만들고 awesome-mcp-servers 등록하기 (0) | 2026.03.20 |