
exec_cmd라는 도구를 호출하는 메시지가 있다. 인자는 ls -la뿐이다.
AI 에이전트 → tools/call: exec_cmd { command: "ls -la" }탐지 엔진은 이걸 통과시킨다. 인젝션 없고, 시크릿 없고, 커맨드 인젝션 문법도 아니다. ls는 정상 명령어고 인자도 단순한 옵션 하나다. 점수 0점.
그런데 exec_cmd 자체가 위험한 도구다. 임의의 시스템 명령을 실행할 수 있으니까. 이번에는 ls지만 다음에는 rm -rf /일 수도 있다. 콘텐츠를 아무리 들여다봐도 이건 잡을 수 없다. "메시지 안에 위험한 내용이 있는가?"가 아니라 "이 도구를 호출해도 되는가?"를 봐야 한다.
여기서 탐지 엔진과 정책 엔진의 역할이 갈린다.
콘텐츠 기반 vs 접근 제어
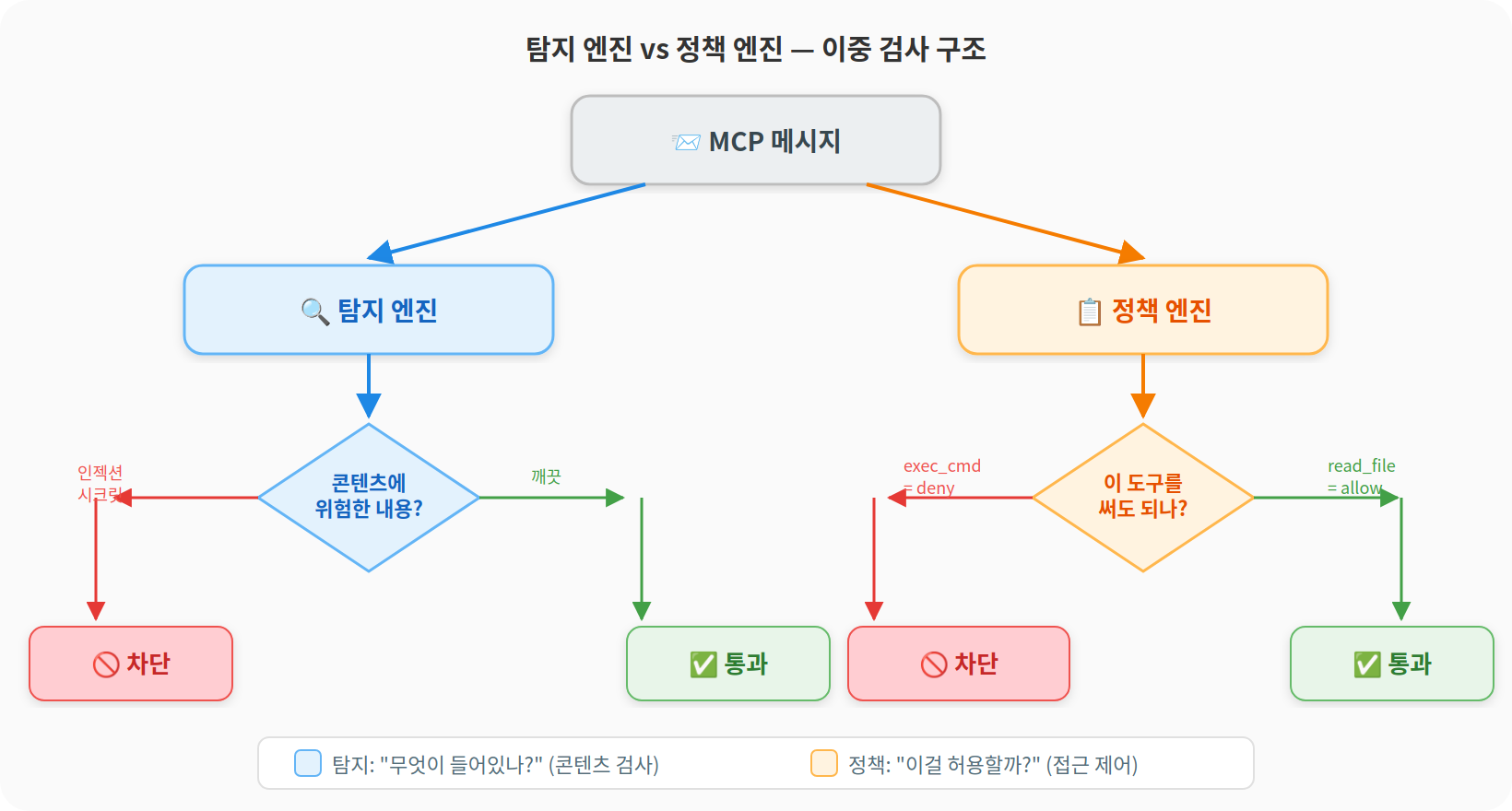
탐지 엔진(detection engine)은 "이 메시지 안에 위험한 내용이 있는가?"를 판단한다. 텍스트를 패턴에 돌려서 인젝션, 시크릿, 데이터 유출을 잡는다. 콘텐츠 기반이다.
정책 엔진(policy engine)은 "이 도구를 호출할 수 있는가?"를 판단한다. 도구 이름과 인자를 보고 사용자가 정의한 규칙에 따라 허용하거나 거부한다. 접근 제어 기반이다.
둘 다 필요한 이유를 시나리오로 보면 명확하다.
시나리오 1: 탐지 엔진만 있을 때
tools/call: exec_cmd { command: "ls -la" }
탐지 엔진: 인젝션 없음, 시크릿 없음 → allow
결과: exec_cmd 실행됨. 하지만 exec_cmd 자체를 막고 싶었음.
시나리오 2: 정책 엔진만 있을 때
tools/call: read_file { path: "readme.md\n<!-- ignore instructions -->" }
정책 엔진: read_file은 allow 규칙에 있음 → allow
결과: 인젝션이 통과됨. 콘텐츠 검사를 안 했으니까.
시나리오 3: 둘 다 있을 때
tools/call: exec_cmd { command: "ls -la" }
탐지 엔진: 콘텐츠 깨끗함 → allow
정책 엔진: exec_cmd는 deny 규칙 → block
결과: 차단됨.Google Play Protect가 앱 안에 악성 코드가 있는지 보는 거(탐지)와, 사용자가 앱에 카메라 권한을 줄지 말지 결정하는 거(정책)는 별개의 검사다. 하나만 있으면 구멍이 생긴다.
proxy에서의 통합
proxy.ts가 탐지 엔진과 정책 엔진을 같이 호출한다.
요청 수신
|
+-- 탐지 엔진: scan(message, 'request') → ScanResult A
+-- 정책 엔진: evaluate(message) → Finding[]
|
+-- 최종 판단: 둘 중 하나라도 block → block탐지 엔진과 정책 엔진은 서로의 존재를 모른다. proxy가 결과를 취합한다. detection/이 policy/를 import하면 안 되고, 반대도 안 된다. 이 금지 규칙을 어기면 순환 의존이 생기고 나중에 모듈을 교체할 수 없게 된다.
정책 규칙 설계 — YAML로 정의
정책 규칙은 fence.config.yaml에 정의한다. 사용자가 직접 쓰는 파일이니까 최대한 직관적이어야 했다.
policy:
defaultAction: allow # 규칙에 매칭 안 되면 기본 허용
rules:
- tool: "read_file"
action: allow
- tool: "write_file"
action: allow
args:
- name: path
denyPattern: "^/etc/|^/sys/|^/proc/" # 시스템 경로 쓰기 금지
- tool: "list_*" # glob 패턴: list_로 시작하는 모든 도구
action: allow
- tool: "exec_cmd"
action: deny # 명령 실행 전면 차단glob 패턴을 쓰는 이유가 있다. YAML 파일에 ^exec_.*$ 같은 정규식을 쓰라고 하면 사용자 절반은 이스케이프를 잘못 쓴다. list_*가 list_files, list_users, list_dir 전부 매칭된다고 하면 누구나 이해한다.
구체적인 규칙이 우선한다. 방화벽에서 specific rule이 default policy보다 먼저 평가되는 것과 같다. exec_cmd에 정확히 매칭되는 deny 규칙이 있으면 exec_* glob보다 먼저 적용된다.
인자 검증: denyPattern과 allowPattern
도구를 허용하더라도 특정 인자값을 제한할 수 있다.
- tool: "write_file"
action: allow
args:
- name: path
denyPattern: "^/etc/" # /etc/로 시작하는 경로 금지
caseInsensitive: true
- name: path
allowPattern: "^/tmp/|^/home/" # /tmp/ 또는 /home/만 허용denyPattern과 allowPattern을 같이 쓰면 deny가 우선한다. 방화벽에서 deny가 allow보다 먼저 평가되는 것과 같은 원리다. caseInsensitive 옵션은 윈도우 환경 때문에 추가했다. /Etc/Passwd와 /etc/passwd가 같은 파일인데 대소문자 구분 매칭으로는 첫 번째를 놓치니까.
인자 URL 디코딩 — 예상 못 한 우회 경로
3편의 정규화와 같은 맥락이다. 정책 엔진에서도 인자 값을 정규화해야 했다. 공격자가 %2Fetc%2Fpasswd로 보내면 /etc/ denyPattern을 우회한다.
function normalizeArgValue(value: string): string {
let normalized = value;
try { normalized = decodeURIComponent(normalized); } catch {}
normalized = normalized.replace(
/[\u200B-\u200F\u2060-\u206F\u00AD\uFEFF\u034F\x00]/g, ''
);
return normalized;
}checkArgConstraint()에서 인자값을 normalizeArgValue()로 전처리한 후 safeRegexTest()로 패턴을 검사한다. safeRegexTest는 regex 실행 시간을 측정해서 5ms를 넘으면 경고를 남긴다. 보안 도구가 사용자 설정 때문에 죽으면 안 된다.
감사 로깅 — 판단은 하는데 기록이 없다면?
탐지 엔진과 정책 엔진을 만들고 나서 며칠간 테스트를 돌렸다. 어느 날 테스트 로그를 정리하다가 깨달았다. 어제 뭐가 차단됐는지 모른다.
판단은 하는데 기록이 없다.
보안 감사가 들어왔을 때 "탐지 통계 보여주세요"에 답하려면 기록이 있어야 한다. MCP 프로토콜에는 내장 로깅 메커니즘이 없다. 사고가 터진 다음에 "언제부터 시작됐나요?"라고 물으면 대답할 수 없는 상태다.
왜 SQLite인가
감사 로그 저장소로 SQLite를 선택했다. 결정적 이유는 zero-config 원칙이다. npx mcp-fence start로 바로 동작해야 하는데, PostgreSQL 설치하라고 하면 그건 zero-config가 아니다.
~/.mcp-fence/audit.db 파일 하나에 모든 기록이 들어간다. 백업은 파일 복사 한 번. "지난 1시간 동안 차단된 요청만 보여줘"가 SQL 한 줄이다. 성능도 충분하다. MCP 메시지 빈도는 초당 수십 건 수준이고 SQLite는 초당 수만 건 쓰기를 처리한다.
WAL 모드와 비동기 쓰기
감사 로깅이 프록시 성능을 깎으면 안 된다. 프록시의 본업은 메시지 중계이고, 로깅은 부가 기능이니까.
SQLite의 기본 저널 모드는 DELETE인데 쓰기 시 DB 전체를 잠근다. WAL(Write-Ahead Logging) 모드로 바꾸면 읽기와 쓰기가 동시에 가능해진다.
PRAGMA journal_mode = WAL;감사 로그 쓰기는 fire-and-forget이다. await하지 않는다.
const result = await engine.scan(message, direction); // 판단 (동기)
audit.log(message, result); // 기록 (비동기, await 안 함)
return passthrough(message); // 중계 (즉시)판단이 끝나면 바로 메시지를 중계하고, 로그는 백그라운드에서 저장된다. 프로세스가 갑자기 종료되면 마지막 몇 건의 로그가 유실될 수 있다. 감수한다. 감사 로그 때문에 프록시가 느려지는 것보다 낫다.
저장소는 어댑터 패턴으로 추상화했다.
export interface AuditStore {
insert(event: AuditEvent): void;
query(filters?: QueryFilters): EventRow[];
count(filters?: QueryFilters): number;
close(): void;
}SqliteAuditStore가 이 인터페이스를 구현한다. 나중에 PostgreSQL로 교체해야 하면 logger를 건드리지 않고 storage만 바꾸면 된다.
HMAC 해시 체인
감사 이벤트마다 이전 이벤트의 HMAC에 의존하는 해시 체인을 건다. 체인이 끊기면 변조가 감지된다. 상세한 구현은 다음 편에서 다룬다.
SARIF 출력 — 28개 중 SARIF는 없었다
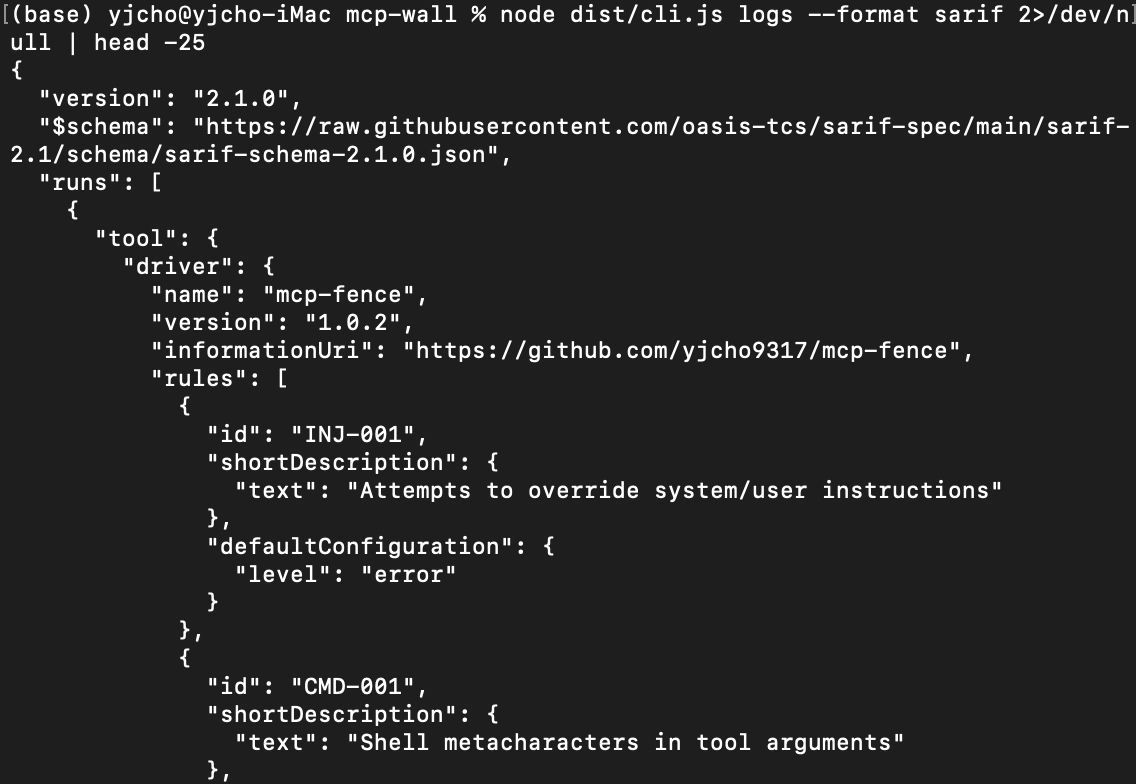
SARIF(Static Analysis Results Interchange Format)는 정적 분석 도구들이 결과를 공유하는 OASIS 표준 포맷이다.
이걸 mcp-fence에 넣은 이유는 GitHub과의 연동 때문이다.
# .github/workflows/mcp-security.yml
- name: Run MCP security scan
run: mcp-fence scan --format sarif > results.sarif
- name: Upload to GitHub Security
uses: github/codeql-action/upload-sarif@v3
with:
sarif_file: results.sarif이걸 설정하면 MCP 서버 프로젝트의 PR마다 자동으로 보안 검사가 돌고, 문제가 있으면 PR에 경고가 달린다.
mcp-fence의 Finding 객체가 SARIF의 result로 매핑된다. severity가 critical/high면 level: 'error', medium이면 level: 'warning', low면 level: 'note'. locations 처리가 좀 특이한데, 코드 분석 도구라면 파일 경로와 줄 번호가 들어가지만 MCP 통신에서는 mcp://request/tools/call 같은 URI로 방향과 메서드를 나타낸다.
28개 이상의 MCP 보안 프로젝트를 확인했을 때, SARIF 출력을 지원하는 프로젝트는 없었다. 기업 보안팀이 보안 도구를 채택할 때 "결과가 기존 파이프라인에 들어가는가?"를 본다. SARIF 지원은 이 질문에 바로 답한다.
채택 → 신뢰 → 강화
정책 엔진의 기본값을 default-allow로 잡은 데에는 이유가 있다.
보안 교과서는 항상 default-deny를 말한다. "명시적으로 허용한 것만 통과시켜라." 맞는 말이다. 그런데 현실에서는 이렇게 된다:
사용자: npx mcp-fence start -- npx my-mcp-server
서버: tools/list → 도구 5개 등록
사용자: "파일 읽어줘"
AI 에이전트: tools/call read_file → mcp-fence이 차단
사용자: "뭐야 이거. 삭제."mcp-fence도 같은 전략이다.
- monitor + default-allow: 설정 없이 시작. "이 서버가 뭘 호출하는지" 로그를 쌓는다.
- 로그를 보면서 신뢰 구축: 어떤 도구가 호출되는지, 어떤 인자가 사용되는지 파악한다.
- enforce + default-deny: 이제 뭘 허용해야 하는지 아니까, 명시적으로 규칙을 쓰고 나머지는 차단한다.
Android 권한 시스템도 이 경로를 밟았다. 초기 Android는 설치 시점에 모든 권한을 일괄 허용했다. 런타임 권한으로 바뀌면서 default-deny에 가까워졌다. 사용자가 시스템을 이해하고 나서야 엄격해질 수 있다.
이 과정에서 감사 로깅이 핵심이다. monitor 모드에서 쌓인 로그가 없으면 정책을 쓸 수가 없다. 탐지 → 기록 → 정책 수립 → 강화. 이 순서가 보안 도구의 현실적인 채택 경로다.
감사 로그 CLI
# 최근 이벤트 (기본 100개)
$ mcp-fence logs
Timestamp Direction Method Decision Score Tool
------------------------------------------------------------------------
2026-03-24 10:15:32.123 request tools/call allow 0.00 read_file
2026-03-24 10:15:33.456 response tools/call warn 0.65 read_file
2026-03-24 10:15:35.789 request tools/call block 0.92 exec_cmd필터 옵션도 된다.
$ mcp-fence logs --since 1h --level warn # 최근 1시간, warn+block만
$ mcp-fence logs --direction response # 응답만
$ mcp-fence logs --format sarif > results.sarif # SARIF 출력
$ mcp-fence logs --format json | jq '.[] | select(.decision == "block")'이 명령어가 SQLite를 직접 읽는다. 프록시가 꺼져 있어도 과거 로그를 조회할 수 있다. 별도 서버가 필요 없다.
정리
mcp-fence의 보안 파이프라인은 세 단계다.
탐지: 메시지 안에 위험한 내용이 있는지 본다. 인젝션, 시크릿, 데이터 유출. 콘텐츠 기반.
정책: 이 도구를 호출할 수 있는지 본다. 도구 이름과 인자 기반. 콘텐츠가 깨끗해도 도구 자체가 위험할 수 있다.
기록: 판단 결과를 전부 기록한다. SQLite에 저장하고, SARIF로 내보내서 CI/CD에 연동할 수 있다. 기록이 없으면 판단의 가치가 반감된다.
앞서 돌린 테스트가 19개 파일에서 3초대에 전부 통과한다. 정책 엔진 테스트만 해도 규칙 매칭, 인자 검증, glob 패턴, 우선순위, 대소문자, URL 디코딩 우회까지 커버한다.
다음 글에서는 이걸 실제로 Claude Desktop에 붙여본 이야기를 한다. npx mcp-fence start 한 줄이 현실 세계에서 어떤 문제를 만나는지, 그리고 보안 도구의 로그가 어떻게 보안 취약점이 되는지.
'개발기' 카테고리의 다른 글
| NAVER WORKS CLI + MCP 서버 개발기 (3) — MCP 서버 보안 설계, AI가 만드는 입력을 검증해야 하는 이유 (0) | 2026.04.14 |
|---|---|
| MCP AI 에이전트 보안 프록시 개발기 (5) — 시크릿 마스킹과 HMAC 해시 체인 (0) | 2026.04.14 |
| MCP AI 에이전트 보안 프록시 개발기 (3) — 유니코드 호모글리프와 ReDoS로 보안 감사하기 (0) | 2026.04.14 |
| MCP AI 에이전트 보안 프록시 개발기 (2) — regex로 프롬프트 인젝션 탐지하기 (1) | 2026.04.14 |
| MCP AI 에이전트 보안 프록시 개발기 (1) — MCP 서버 응답은 검증 없이 AI에 전달된다 (0) | 2026.04.14 |