
작년부터 온디바이스 AI에 관심이 많았다. 딥페이크 탐지 프로젝트에서 모델을 단말에 올리려고 경량화를 시도해봤고, 보이스피싱 탐지는 Qwen 경량 모델까지 써봤지만 온디바이스를 목표로 한 연구 단계에서 멈췄다. 하드웨어 제약이 너무 컸다. 딥페이크 쪽은 결국 클라우드로 돌렸다.
그때 양자화, 프루닝, 지식 증류를 직접 실험해봤다. 어디까지 줄일 수 있는지, 정확도는 얼마나 버틸 수 있는지 확인하고 싶었다.
당시엔 정리만 해두고 글로 올리진 않았다.
그런데 최근에 상황이 바뀌었다. 구글이 온디바이스용 경량 모델 Gemma 4(E2B/E4B)를 내놓고, KV 캐시를 6배 압축하는 TurboQuant까지 발표했다. 경량화가 다시 화두다.
그때 정리해둔 걸 공유해보려 한다. 이번 글은 양자화다.
양자화가 뭔데
숫자 정밀도를 낮추는 거다.
딥러닝 모델의 가중치가 보통 FP32로 저장되어 있다. 32비트 부동소수점. 0.123456789... 이런 식으로 소수점 7자리까지 표현할 수 있다.
INT8로 바꾸면 256개 정수만 표현할 수 있다. signed면 -128127, unsigned(UINT8)면 0255. 소수점은 아예 없어진다. 대신 메모리는 1바이트만 쓴다. FP32의 1/4.
소수점 값들이 정수로 바뀐다. FP32 범위를 몇 단계(256개)로 쪼개서 가장 가까운 정수에 매핑하는 식이다. 구체적인 매핑 값은 scale과 zero_point로 결정된다(뒤에서 설명).
이론적으로:
- FP32 → FP16: 메모리 50% 감소
- FP32 → INT8: 메모리 75% 감소
진짜 이만큼 줄어드는지, 정확도는 얼마나 떨어지는지 직접 확인해보고 싶었다.
실험 설계
CIFAR-10으로 테스트하기로 했다. 이미지 분류 문제라 간단하고, 데이터셋도 바로 쓸 수 있다.
CIFAR-10: 비행기, 자동차, 새, 고양이 등 10개 클래스를 분류하는 문제. 딥러닝 입문용으로 많이 쓴다.
def create_base_model():
model = keras.Sequential([
# Block 1
keras.layers.Conv2D(32, 3, padding='same', activation='relu',
input_shape=(32, 32, 3)),
keras.layers.Conv2D(32, 3, padding='same', activation='relu'),
keras.layers.MaxPooling2D(),
keras.layers.Dropout(0.2),
# Block 2
keras.layers.Conv2D(64, 3, padding='same', activation='relu'),
keras.layers.Conv2D(64, 3, padding='same', activation='relu'),
keras.layers.MaxPooling2D(),
keras.layers.Dropout(0.3),
# Classifier
keras.layers.Flatten(),
keras.layers.Dense(256, activation='relu'),
keras.layers.Dropout(0.4),
keras.layers.Dense(10, activation='softmax')
])
return model20 epoch로 학습시키니까 77.88% 정확도가 나왔다. 양자화 테스트하기엔 충분하다.

TFLite 변환부터
TFLite를 사용하면 비교적 간단하게 양자화가 가능하다. 그래서 양자화 전에 일단 TFLite로 변환부터 해봤다. 양자화 없이.
converter = tf.lite.TFLiteConverter.from_keras_model(base_model)
tflite_model = converter.convert()모델이 13MB였는데, TFLite로 바꾸니까 4.3MB가 됐다. 양자화 안 했는데도 66% 줄었다. H5 파일은 추론에 필요한 가중치 외에도 옵티마이저 상태(Adam의 m, v 같은 학습용 변수)를 함께 저장한다. TFLite는 추론에 필요한 것만 남기니까 그만큼 줄어든 거다.
FP16 양자화
첫 번째 시도. FP16으로 바꿔봤다.
converter = tf.lite.TFLiteConverter.from_keras_model(base_model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.float16]
tflite_fp16 = converter.convert()결과: 2.2MB. FP32 TFLite 대비 딱 50% 줄었다. 이론대로다.
정확도는? 77.88%. 똑같다. 손실 0%.
근데 속도는 사실상 변화가 없다. 754μs → 755μs. 측정 노이즈 수준이다. FP16 연산을 네이티브로 가속하는 하드웨어가 아니면 CPU에서는 이득이 거의 없다.
INT8 양자화
INT8 변환은 좀 다르다. representative_dataset이라는 게 필요하다.
처음엔 왜 이게 필요한지 감이 안 왔다. 가중치는 이미 값이 정해져 있으니 그냥 양자화하면 되는데, Activation은 입력에 따라 값이 달라진다. 그러니까 실제 데이터 몇 개를 넣어보고 범위를 측정해야 한다. 이걸 Calibration이라고 부른다.
def representative_dataset():
for i in range(100):
yield [x_train[i:i+1]]100개 샘플을 넣어주면 TensorFlow가 각 레이어의 Activation 범위를 측정한다. 그걸로 scale이랑 zero_point를 계산한다.
converter = tf.lite.TFLiteConverter.from_keras_model(base_model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_dataset
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.uint8
converter.inference_output_type = tf.uint8
tflite_int8 = converter.convert()결과: 1.1MB. 원본 FP32 TFLite 대비 75% 감소. 여기까지는 교과서 그대로다.
변환하고 나서 궁금해서 내부를 열어봤다. 양자화된 가중치에는 scale이랑 zero_point라는 값이 붙어 있다.
양자화 수식은 이렇다:
INT8_value = round(FP32_value / scale) + zero_point
역변환:
FP32_value ≈ scale × (INT8_value - zero_point)역변환이 중요하다. 추론할 때는 INT8로 돌리고, 결과 꺼낼 때 이 식으로 다시 FP32로 되돌린다. 3편 Android 코드에서 이 역변환이 다시 나온다.
scale은 압축 비율이다. FP32 범위를 INT8 범위로 얼마나 쪼갤지 정하는 값.
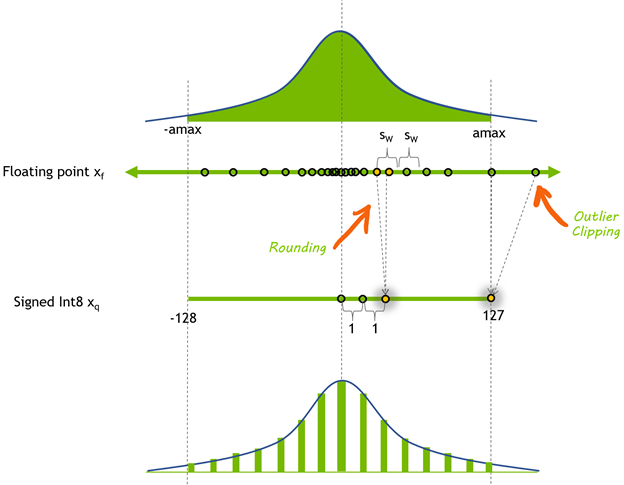
zero_point는 한동안 왜 필요한지 감이 안 왔다. 간단히 말하면 FP32의 0.0이 INT8에서 몇이 되는지 알려주는 값이다. 가중치가 -0.5 ~ 2.0처럼 한쪽으로 치우쳐 있으면 0.0이 INT8의 0이 아닌 다른 값에 매핑되는데, 그 "다른 값"이 zero_point다. 대칭 범위면 0, 비대칭이면 0이 아닌 숫자. 실무에선 TensorFlow가 알아서 계산한다. 이런 게 있구나 정도만 알고 넘어갔다.
결과 정리
최종 결과를 정리하면 이렇다.
크기:
- H5 원본: 13.1MB
- FP32 TFLite: 4.3MB (67% 감소)
- FP16 TFLite: 2.1MB (83% 감소)
- INT8 TFLite: 1.1MB (92% 감소)
속도 (데스크톱 CPU 기준):
- FP32: 754.7μs
- FP16: 755.4μs (1.00배, 변화 없음)
- INT8: 169.8μs (4.44배)
INT8이 빨라지는 건 메모리 대역폭이 1/4로 줄고, CPU의 SIMD 명령어가 한 번에 더 많은 숫자를 처리할 수 있어서다. FP16이 거의 안 빨라진 거랑 대비된다. FP16은 네이티브로 가속하는 CPU가 아니면 이득이 없는데, INT8은 그렇지 않다.
정확도:
- 전부 77.88%. 손실 없음.
CIFAR-10이 비교적 단순한 문제라서 그런 것 같다. ImageNet 같은 복잡한 데이터셋에서는 0.5~2%p 정도 손실이 생긴다고 한다.

결론
양자화는 생각보다 쉬웠다. 코드 몇 줄이면 되고, 이 실험에서는 정확도 손실이 없었다. 다만 이건 CIFAR-10 기준이다. 복잡한 모델에서는 1~2%p 손실을 감수해야 할 때가 있고, 그게 서비스 지표에 치명적이면 얘기가 달라진다.
그래서 "양자화는 무조건 해라"가 아니라 "먼저 해봐라"가 맞는 말인 것 같다. 이만한 비용으로 이 정도 효과를 내는 기법은 드물다.
이번 실험은 학습 끝난 모델을 양자화하는 PTQ(Post-Training Quantization)로 충분했다. 손실이 안 나왔으니까. QAT(Quantization-Aware Training)는 학습 과정에 양자화를 섞는 방식이라 비용이 더 드는데, PTQ에서 정확도가 유의미하게 깎일 때만 꺼내는 카드다. CIFAR-10처럼 단순한 문제에 굳이 쓸 이유는 없었다.
작년에 클라우드로 돌릴 수밖에 없었던 건 모델이 무거워서였다. 그때 이걸 먼저 해봤으면 단말에서 돌리는 선택지가 있었을지도 모른다.
소스 코드
https://github.com/yjcho9317/CIFAR10_OnDevice
참고 자료
- 딜로이트 온디바이스 AI 분석: https://www.deloitte.com/kr/ko/Industries/technology/analysis/on-device-ai.html
- IBM 양자화 설명: https://www.ibm.com/kr-ko/think/topics/quantization
- PyTorch INT8 양자화: https://pytorch.kr/blog/2023/int8-quantization/
- 우아한형제들 양자화 인식 훈련: https://techblog.woowahan.com/21176/
'AI' 카테고리의 다른 글
| 온디바이스 AI 경량화 (3) — LiteRT로 INT8 모델 Android 배포와 GPU Delegate의 함정 (0) | 2026.04.17 |
|---|---|
| 온디바이스 AI 경량화 (2) — 프루닝과 지식 증류 실전 비교 (AGP, Temperature, KL Divergence) (0) | 2026.04.17 |
| MLOps 구축기 (5) - MLflow 기반 MLOps 파이프라인 전체 정리 (1) | 2026.03.13 |
| MLOps 구축기 (4) - GitHub Actions CI/CD와 Prometheus + Grafana 모니터링 (0) | 2026.03.13 |
| MLOps 구축기 (3) - MLflow 모델을 FastAPI로 서빙하기 (0) | 2026.03.08 |