
3편까지 모델 학습, MLflow 실험 기록, 모델 레지스트리 등록, FastAPI 서빙까지 만들었다.
문제는 하나다.
전부 수동이다.
코드를 수정할 때마다 직접 해야 했다.
python src/train_experiments.py
python src/register_best_model.py서빙 서버 상태도 로그를 직접 확인해야 했다.
이 정도는 개인 실험에서는 괜찮다.
하지만 팀 프로젝트나 반복 실험에서는 금방 한계가 온다.
그래서 이번 편에서는 두 가지를 붙인다. GitHub Actions로 코드 push 시 학습 파이프라인을 자동 실행하는 CI/CD, 그리고 Prometheus + Grafana로 서빙 서버 상태를 실시간으로 확인하는 모니터링이다.
CI/CD: GitHub Actions로 학습 파이프라인 자동화
왜 CI/CD가 필요한가
지금까지의 워크플로우는 이렇다.
- 학습 코드 수정
train_experiments.py실행register_best_model.py실행- 결과 확인
이걸 사람이 매번 돌리는 건 비효율적이다.
코드가 push되면 자동으로 다음이 실행되는 게 자연스럽다.
학습 → 모델 등록 → 추론 검증일반 소프트웨어 개발에서 push하면 빌드와 테스트가 자동으로 도는 것과 같은 개념이다.
워크플로우 구성
GitHub Actions 워크플로우 파일 하나로 구성했다.
# .github/workflows/train_and_register.yml
name: Train and Register Model
on:
push:
paths:
- 'src/train_experiments.py'
- 'src/register_best_model.py'
- '.github/workflows/train_and_register.yml'
jobs:
train:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v4
- name: Start MLflow infrastructure
run: |
docker compose up -d postgres minio create-bucket mlflow
echo "Waiting for services to be ready..."
sleep 30
- name: Check MLflow health
run: |
curl -f http://localhost:5001/health || (docker compose logs mlflow && exit 1)
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: '3.11'
- name: Install dependencies
run: |
pip install mlflow scikit-learn numpy
- name: Run training experiments
env:
MLFLOW_TRACKING_URI: http://localhost:5001
run: |
python src/train_experiments.py
- name: Register best model
env:
MLFLOW_TRACKING_URI: http://localhost:5001
run: |
python src/register_best_model.py
- name: Verify model prediction
env:
MLFLOW_TRACKING_URI: http://localhost:5001
run: |
python src/predict.py
- name: Cleanup
if: always()
run: |
docker compose down설계하면서 고민했던 것들
언제 워크플로우를 실행할 것인가
처음에는 push마다 실행되도록 만들었다.
하지만 README 수정 같은 경우에도 학습이 돌았다.
완전히 낭비다.
그래서 다음 파일이 변경됐을 때만 실행하도록 제한했다.
src/train_experiments.py
src/register_best_model.py
workflow 파일MLflow 서버를 어떻게 사용할 것인가
선택지는 두 가지였다. 외부 MLflow 서버를 사용하거나, CI 환경에서 직접 인프라를 실행하거나.
외부 서버는 네트워크, 인증, 보안 설정이 복잡해진다.
그래서 CI 런너 내부에서 Docker Compose로 인프라를 띄우는 방식을 선택했다.
docker compose up -d postgres minio mlflow학습이 끝나면 바로 정리된다.
CI 환경에서는 이 방식이 가장 단순하다.
sleep 30
이 부분은 조금 투박하다.
sleep 30PostgreSQL과 MinIO가 완전히 준비될 때까지 기다리는 가장 단순한 방법이다.
프로덕션 환경이라면 health check를 반복해서 확인하는 방식이 더 적절하다.
하지만 CI 환경에서는 이 정도로 충분하다.
Cleanup 단계
워크플로우가 실패하면 컨테이너가 그대로 남을 수 있다.
그래서 마지막 단계에 다음 옵션을 넣었다.
if: always()성공 여부와 상관없이 Docker 컨테이너를 정리한다.
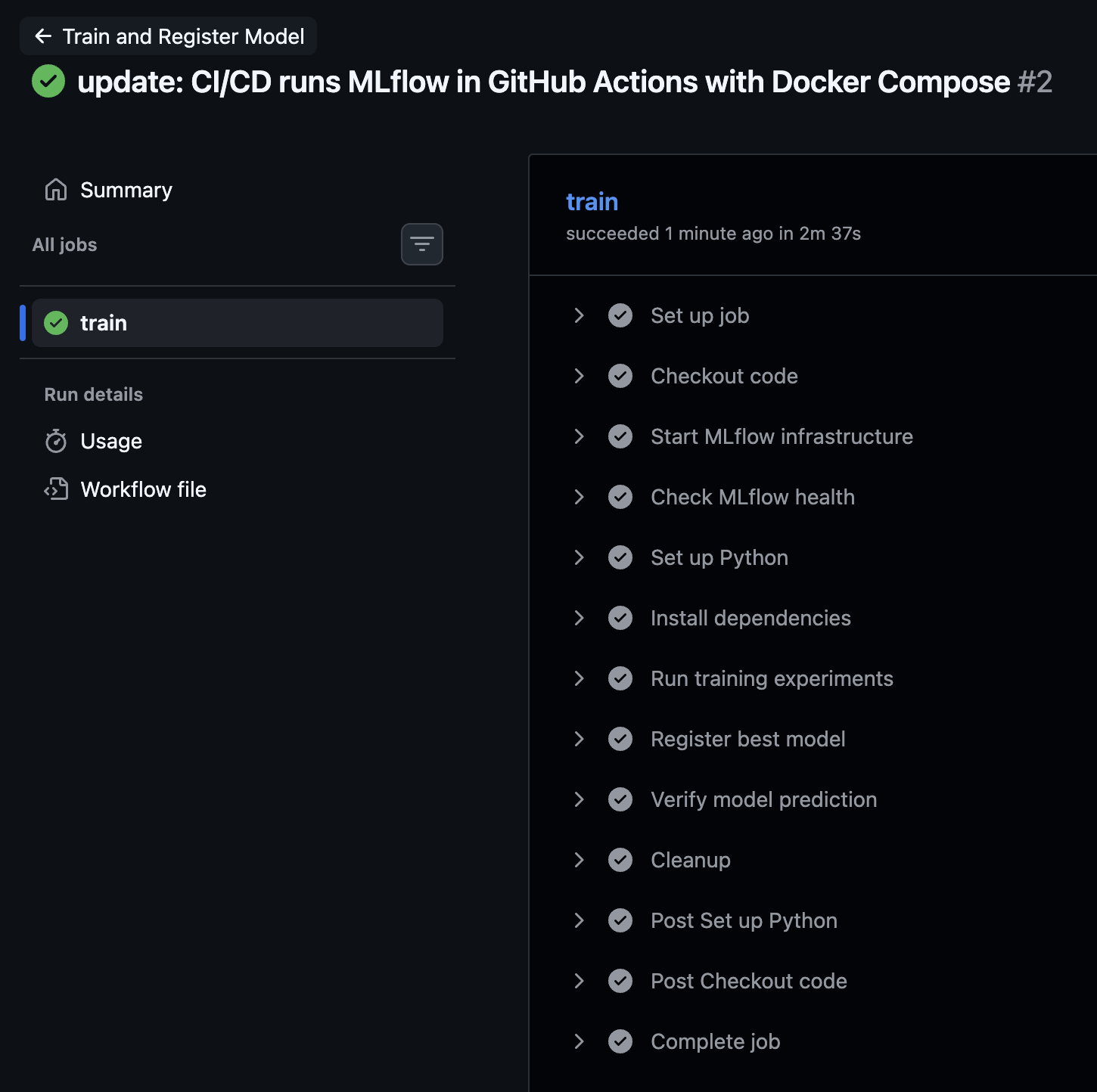
실행 결과
학습 코드를 수정하고 push하면 GitHub Actions에서 자동으로 파이프라인이 실행된다.
전체 과정은 약 2분 30초 정도 걸렸다.
모니터링: Prometheus + Grafana
모델 배포는 끝이 아니라 시작이다.
운영 환경에서는 특정 시간대에 요청이 몰리거나, 응답 시간이 점점 느려지거나, 모델 업데이트 이후 에러율이 올라가는 문제들이 발생한다.
문제는 이걸 바로 알기 어렵다는 것이다.
그래서 모니터링을 붙인다.
구성은 단순하다.
Prometheus → 메트릭 수집
Grafana → 시각화서빙 코드에 메트릭 추가
3편에서 만든 src/serve.py에 Prometheus 메트릭을 추가한다.
변경 전(3편)에는 단순히 /health와 /predict 엔드포인트만 있었다. 여기에 prometheus-client 라이브러리를 사용해서 요청 수와 응답 시간을 기록하는 코드를 추가한다.
먼저 의존성을 설치한다.
pip install prometheus-client변경된 전체 코드는 이렇다.
# src/serve.py
import os
import time
import mlflow
import numpy as np
from fastapi import FastAPI
from pydantic import BaseModel
from prometheus_client import Counter, Histogram, generate_latest, CONTENT_TYPE_LATEST
from fastapi.responses import Response
mlflow.set_tracking_uri(os.getenv("MLFLOW_TRACKING_URI", "http://localhost:5001"))
model = mlflow.sklearn.load_model("models:/digits-classifier/1")
app = FastAPI(title="Digits Classifier API")
# Prometheus 메트릭 정의
REQUEST_COUNT = Counter(
"prediction_requests_total",
"Total prediction requests",
["status"]
)
REQUEST_LATENCY = Histogram(
"prediction_latency_seconds",
"Prediction request latency in seconds",
buckets=[0.01, 0.025, 0.05, 0.1, 0.25, 0.5, 1.0]
)
class PredictRequest(BaseModel):
features: list[list[float]]
class PredictResponse(BaseModel):
predictions: list[int]
@app.get("/health")
def health():
return {"status": "ok"}
@app.get("/metrics")
def metrics():
return Response(content=generate_latest(), media_type=CONTENT_TYPE_LATEST)
@app.post("/predict", response_model=PredictResponse)
def predict(req: PredictRequest):
start = time.time()
try:
X = np.array(req.features)
preds = model.predict(X).tolist()
REQUEST_COUNT.labels(status="success").inc()
return PredictResponse(predictions=preds)
except Exception as e:
REQUEST_COUNT.labels(status="error").inc()
raise e
finally:
REQUEST_LATENCY.observe(time.time() - start)3편과 비교해서 달라진 부분은 세 가지다.
Counter는 누적 요청 수를 기록한다. status 라벨로 성공/실패를 구분한다.
Histogram은 응답 시간의 분포를 기록한다. buckets에 정의한 구간별로 몇 건이 해당하는지 추적한다.
/metrics 엔드포인트가 추가됐다. Prometheus가 이 엔드포인트를 주기적으로 호출해서 메트릭을 수집한다.
/predict 엔드포인트에서는 요청이 들어올 때마다 성공/실패 카운터를 올리고, finally 블록에서 소요 시간을 기록한다.
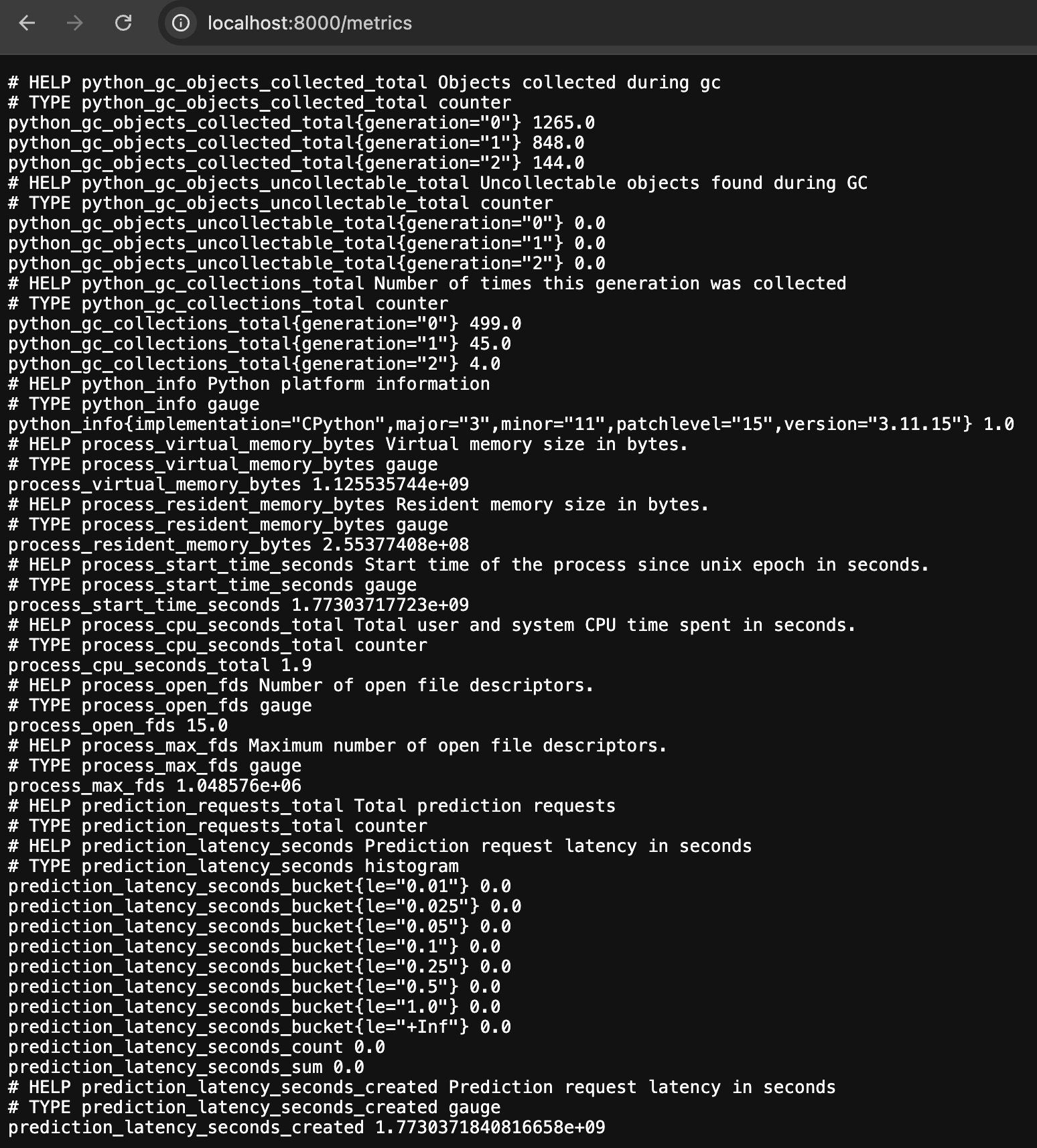
브라우저에서 http://localhost:8000/metrics에 접속하면 Prometheus 형식의 메트릭 데이터가 보인다. prediction_requests_total, prediction_latency_seconds 같은 커스텀 메트릭과 함께 Python 프로세스의 메모리 사용량 같은 기본 메트릭도 자동으로 노출된다.
Dockerfile.serve 업데이트
prometheus-client가 추가됐으니 Dockerfile.serve도 업데이트해야 한다.
# Dockerfile.serve
FROM python:3.11-slim
WORKDIR /app
RUN pip install mlflow scikit-learn fastapi uvicorn prometheus-client
COPY src/serve.py .
CMD ["uvicorn", "serve:app", "--host", "0.0.0.0", "--port", "8000"]3편에서 만든 Dockerfile과 동일한데, pip install에 prometheus-client만 추가됐다.
Docker Compose에 Prometheus와 Grafana 추가
기존 docker-compose.yml에 두 서비스를 추가한다.
prometheus:
image: prom/prometheus
ports:
- "9090:9090"
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
depends_on:
- serving
restart: unless-stopped
grafana:
image: grafana/grafana
ports:
- "3000:3000"
environment:
GF_SECURITY_ADMIN_PASSWORD: admin
depends_on:
- prometheus
restart: unless-stoppedPrometheus 설정 파일도 필요하다.
# prometheus.yml
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'serving'
static_configs:
- targets: ['serving:8000']
metrics_path: '/metrics'scrape_interval: 15s는 15초마다 서빙 서버의 /metrics를 호출해서 메트릭을 수집한다는 의미다. targets에 Docker 서비스 이름(serving:8000)을 쓴다. Docker 네트워크 안에서는 서비스 이름으로 접근할 수 있다.
전체 인프라 구조
이제 인프라는 7개 서비스로 구성된다.
[ docker-compose.yml ]
├── postgres ← 실험 메타데이터 저장
├── minio ← 모델 아티팩트 저장
├── create-bucket ← MinIO 버킷 초기화
├── mlflow ← 실험 추적 + 모델 레지스트리
├── serving ← FastAPI 추론 API + 메트릭
├── prometheus ← 메트릭 수집
└── grafana ← 대시보드 시각화실행은 동일하다.
docker compose up -d --build
Grafana 대시보드 구성
접속 및 로그인
http://localhost:3000에 접속한다.
로그인은 docker-compose.yml에서 설정한 GF_SECURITY_ADMIN_PASSWORD 값이다 (이 글에서는 admin / admin).
데이터 소스 연결
Connections → Data sources → Add data source → Prometheus를 선택한다.
Prometheus server URL에 http://prometheus:9090을 입력한다. Grafana도 Docker 안에서 돌아가니까 localhost가 아니라 Docker 서비스 이름(prometheus)으로 접근해야 한다.
Save & test를 누르면 "Successfully queried the Prometheus API" 메시지가 나온다. 이게 나오면 연결 완료.
대시보드 패널 만들기
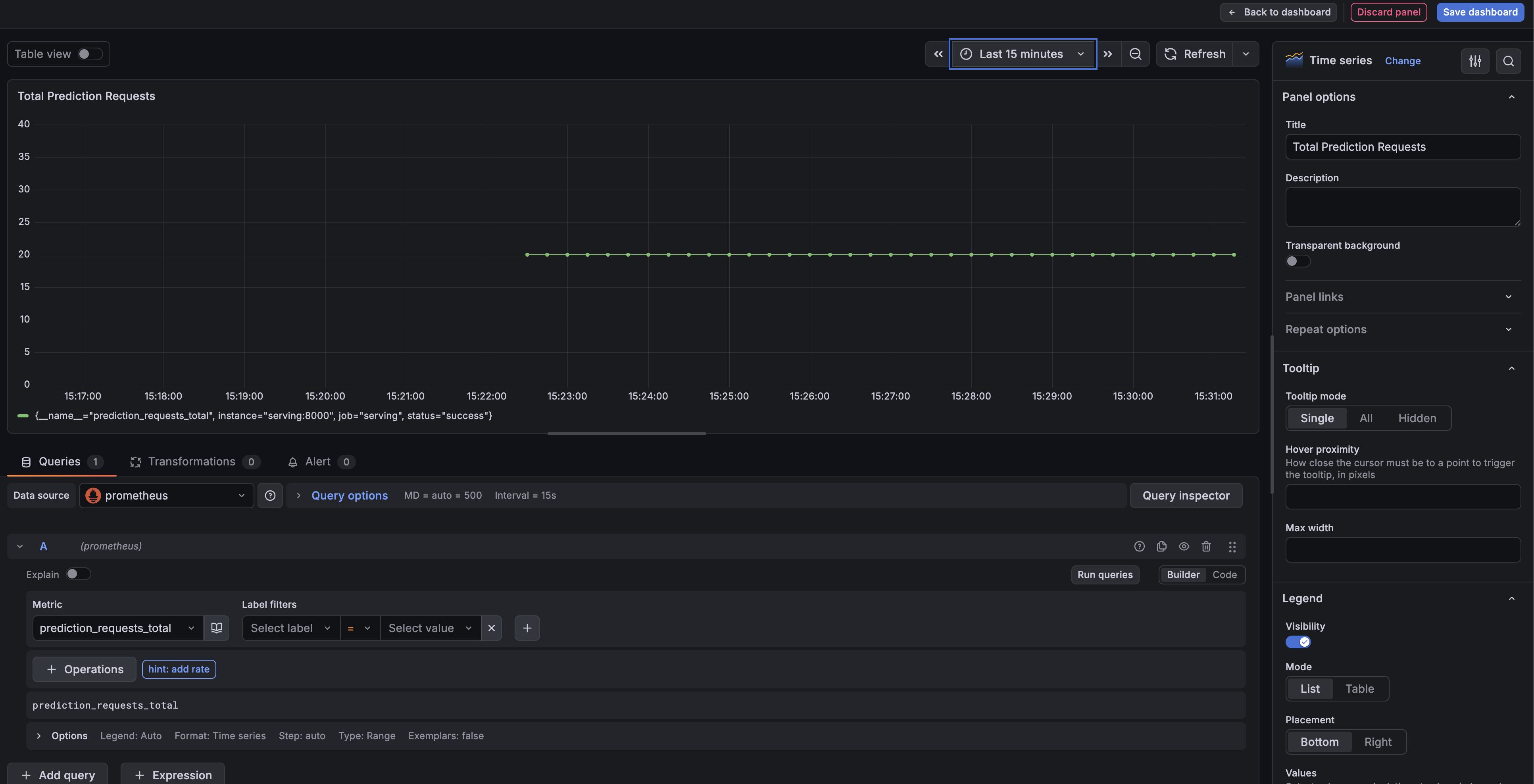
Dashboards → New dashboard → Add visualization으로 패널을 만든다.
3개 패널을 구성했다.
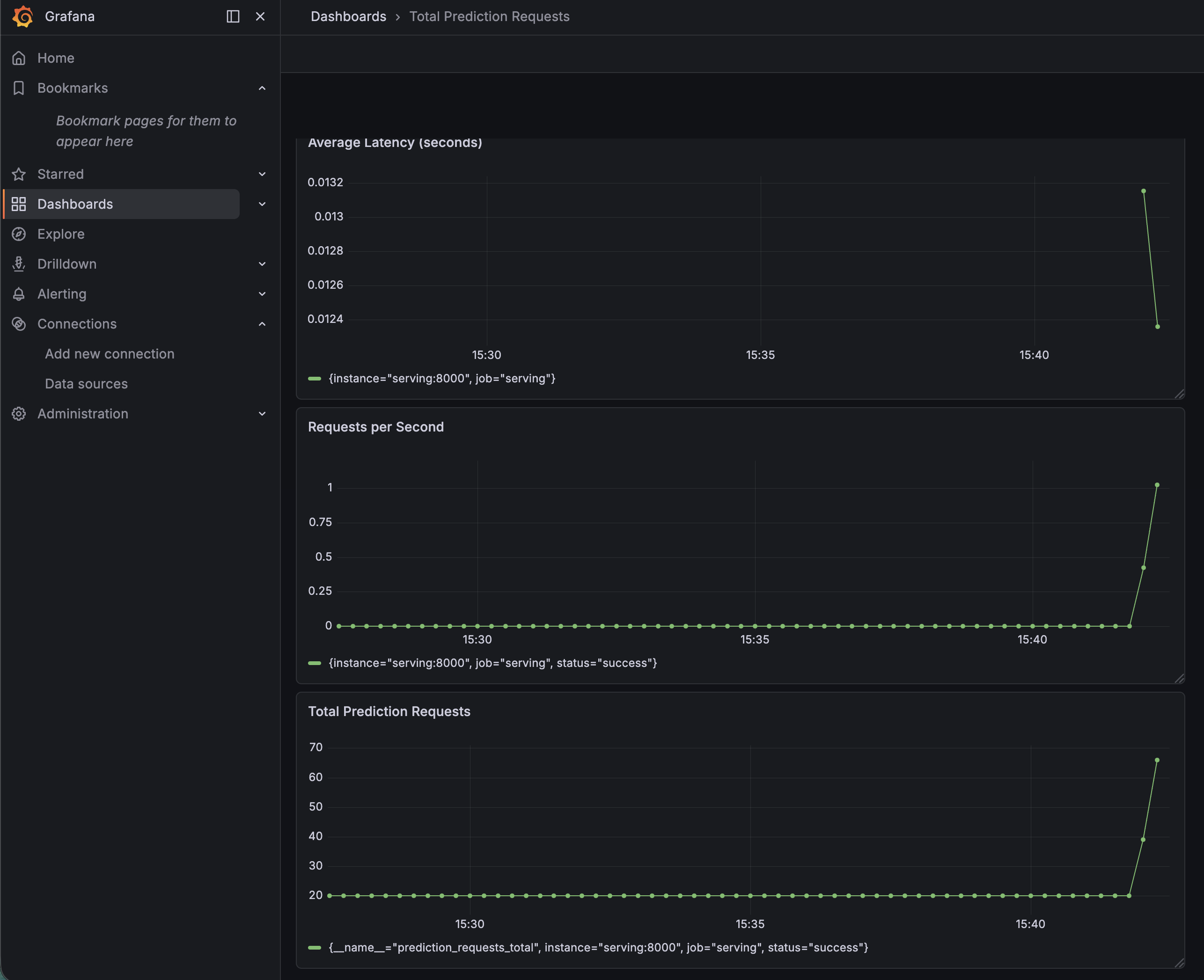
Total Prediction Requests — 누적 요청 수
prediction_requests_totalRequests per Second — 초당 요청 수
rate(prediction_requests_total[1m])Average Latency — 평균 응답 시간
rate(prediction_latency_seconds_sum[1m]) / rate(prediction_latency_seconds_count[1m])각 패널에서 Data source를 prometheus로 선택하고, 위 쿼리를 입력한 뒤 Run queries를 누르면 그래프가 그려진다.
테스트
서빙 서버에 요청을 몇 번 보내본다.
curl -X POST http://localhost:8000/predict \
-H "Content-Type: application/json" \
-d '{"features": [[0,0,5,13,9,1,0,0,0,0,13,15,10,15,5,0,0,3,15,2,0,11,8,0,0,4,12,0,0,8,8,0,0,5,8,0,0,9,8,0,0,4,11,0,1,12,7,0,0,2,14,5,10,12,0,0,0,0,6,13,10,0,0,0]]}'Grafana 대시보드를 보면 그래프가 실시간으로 반응한다. 총 요청 수가 올라가고, 초당 요청 수에 스파이크가 찍히고, 평균 응답 시간이 약 13ms로 안정적으로 나왔다.
정리
이번 편에서 두 가지를 추가했다. GitHub Actions로 학습 파이프라인을 자동화하고, Prometheus + Grafana로 서빙 모니터링을 붙였다.
이제 흐름은 이렇게 정리된다.
학습
→ 실험 추적
→ 모델 비교
→ 모델 등록
→ 서빙
→ CI/CD
→ 모니터링docker compose up -d 한 번으로 전체 인프라가 올라가고,
코드를 push하면 학습 파이프라인이 자동으로 실행된다.
MLOps의 기본 사이클은 이 구조로 대부분 설명된다.
사용한 도구
- GitHub Actions (CI/CD 파이프라인)
- Prometheus (메트릭 수집)
- Grafana (대시보드 시각화)
- prometheus-client (Python 메트릭 라이브러리)
- FastAPI + Uvicorn (추론 API 서버)
- Docker Compose (전체 인프라 오케스트레이션)
'AI' 카테고리의 다른 글
| 온디바이스 AI 경량화 (1) — INT8 양자화로 CIFAR-10 모델 92% 줄이기 (TFLite PTQ) (0) | 2026.04.17 |
|---|---|
| MLOps 구축기 (5) - MLflow 기반 MLOps 파이프라인 전체 정리 (1) | 2026.03.13 |
| MLOps 구축기 (3) - MLflow 모델을 FastAPI로 서빙하기 (0) | 2026.03.08 |
| MLOps 구축기 (2) - MLflow 하이퍼파라미터 실험 관리와 Model Registry (0) | 2026.03.08 |
| MLOps 구축기 (1) - MLflow Tracking Server 구축 (Docker Compose + PostgreSQL + MinIO) (0) | 2026.03.05 |