
1편에서 양자화로 모델을 92% 줄였고, 2편에서 프루닝과 지식 증류까지 실험해봤다. 경량화는 끝났다.
그러면 주제인 온디바이스는?
Python에서 77.88% 나온 INT8 모델이 Android 단말에서도 같은 정확도와 속도를 낼지, 직접 올려봤다.
프레임워크 선택
내가 고른 건 LiteRT(구 TensorFlow Lite)다. 이유는 단순했다. 학습을 Keras로 했으니 변환이 .tflite 한 번으로 끝나고, INT8 양자화된 모델을 그대로 들고 올 수 있고, GPU Delegate까지 바로 붙는다. 선택이라기보다는 기본값이었다.
선택지를 비교하긴 했다. Android 모바일 배포에서는 LiteRT / ONNX Runtime / ExecuTorch 셋이 주로 꼽힌다.
| 구분 | LiteRT | ONNX Runtime | ExecuTorch |
|---|---|---|---|
| 개발사 | Microsoft | Meta | |
| 모델 형식 | .tflite | .onnx | .pte |
| 강점 | 모바일 생태계 성숙 | 프레임워크 중립 | PyTorch 네이티브, LLM 특화 |
규칙은 간단하다. 학습한 프레임워크의 네이티브 런타임을 쓰면 된다. TensorFlow → LiteRT, PyTorch → ExecuTorch, 프레임워크가 섞이는 팀이면 ONNX Runtime. 모바일 런타임 자체 성능은 벤치마크마다 LiteRT가 앞선다는 결과가 많다. Samsung S21 벤치마크 기준 LiteRT 23ms, ONNX Runtime 31ms, PyTorch Mobile 38ms (DigitalOcean 비교 자료). 물론 NNAPI나 vendor delegate 붙이면 순위가 바뀌기도 하니까 타깃 디바이스에서 직접 재보는 게 맞다.
ONNX를 "주류"라고 부르는 건 모델 교환 포맷 얘기지 모바일 런타임 얘기가 아니다. 이걸 구분 안 하면 프레임워크 고르는 데 시간을 잘못 쓴다.
프로젝트 설정
모델 파일을 app/src/main/assets/에 넣고, Gradle을 설정한다.
android {
androidResources {
noCompress += "tflite" // 압축 방지 (필수!)
}
}
dependencies {
implementation("org.tensorflow:tensorflow-lite:2.14.0")
implementation("org.tensorflow:tensorflow-lite-support:0.4.4")
implementation("org.tensorflow:tensorflow-lite-gpu:2.14.0")
implementation("org.tensorflow:tensorflow-lite-gpu-api:2.14.0")
}noCompress를 안 넣으면 모델 로드가 실패한다. Android Gradle 플러그인 4.1부터는 .tflite가 기본으로 noCompress에 들어가 있긴 한데, 명시적으로 넣어두는 게 안전하다.
ML 모델은 일반 앱보다 메모리를 많이 쓴다. 큰 모델(수백 MB 이상)을 올릴 거면 AndroidManifest.xml에 대규모 힙 설정을 넣어준다.
<application
android:largeHeap="true"
android:hardwareAccelerated="true">내 모델은 1.1MB라 사실 필요 없지만, 실서비스에서는 모델이 더 클 수 있으니 미리 넣어두는 편이다.
모델 로드와 추론
모델을 로드하고 추론하는 코드는 크게 복잡하지 않다.
class TFLiteClassifier(
private val context: Context,
private val modelPath: String = "base_int8.tflite",
private val numThreads: Int = 4
) {
private var interpreter: Interpreter? = null
init {
val options = Interpreter.Options()
options.setNumThreads(numThreads)
interpreter = Interpreter(loadModelFile(), options)
}
private fun loadModelFile(): MappedByteBuffer {
val fileDescriptor = context.assets.openFd(modelPath)
val inputStream = FileInputStream(fileDescriptor.fileDescriptor)
val fileChannel = inputStream.channel
return fileChannel.map(
FileChannel.MapMode.READ_ONLY,
fileDescriptor.startOffset,
fileDescriptor.declaredLength
)
}
}MappedByteBuffer로 모델을 메모리에 올리고, Interpreter를 만들면 된다. 추론이 끝나면 interpreter.close()로 메모리를 해제해야 한다.
INT8 모델의 입력 처리
여기가 제일 헷갈릴 수 있는 부분이다.
Python에서 학습할 때는 이미지를 0255에서 01로 정규화해서 Float로 넣었다. 근데 INT8 양자화된 모델은 입력을 UINT8(0~255)로 받는다. Android에서는 Float를 다시 UINT8로 바꿔서 넣어야 한다.
처음엔 단순하게 생각했다. 학습 때 /255로 줄였으니까 반대로 *255 해주면 된다고.
// 처음 쓴 코드
val uint8Value = (pixel * 255f).toInt().coerceIn(0, 255)이번 모델에서는 이게 맞았다. Python과 Android 정확도가 똑같이 78.90%로 나왔다. 그런데 돌아보면 이건 이 모델에 한해 맞은 거였다. 이번 모델은 학습할 때 입력을 0~1로 정규화했고 inference_input_type=tf.uint8로 변환했다. 그래서 입력 tensor의 scale=1/255, zero_point=0이 나온다. 이 경우에만 pixel * 255가 정답이다.
다른 모델(예를 들어 ImageNet mean/std 정규화로 학습된 모델)을 가져오면 scale/zero_point가 전혀 다른 값이 된다. 그러면 *255는 그냥 틀린 값이다.
원칙은 1편에서 봤던 양자화 수식이다.
INT8_value = round(FP32_value / scale) + zero_point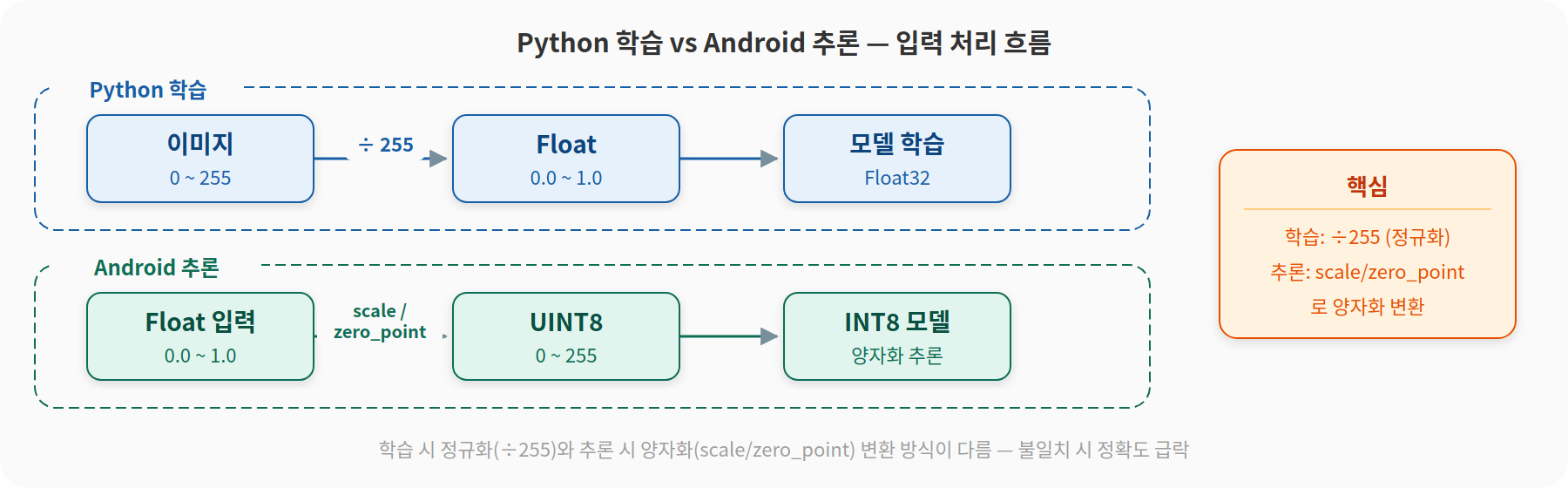
그래서 쓸 때는 모델에서 scale/zero_point를 직접 읽어서 변환하는 게 안전하다. 이번 모델에서는 이 식이 pixel * 255로 단순화될 뿐이다.
// 입력 tensor의 quantization 파라미터를 먼저 읽는다
val inputParams = interpreter.getInputTensor(0).quantizationParams()
val inScale = inputParams.scale
val inZeroPoint = inputParams.zeroPoint
val inputBuffer = ByteBuffer.allocateDirect(1 * 32 * 32 * 3).apply {
order(ByteOrder.nativeOrder())
}
for (i in imageFloats.indices) {
val pixel = imageFloats[i]
val quantized = ((pixel / inScale) + inZeroPoint).toInt().coerceIn(0, 255)
inputBuffer.put(quantized.toByte())
}
inputBuffer.rewind()출력도 UINT8로 나온다. 이쪽은 같은 식을 역으로 풀어서(FP32 ≈ scale × (INT8 - zero_point)) FP32로 되돌린다.
val rawOutput = ByteArray(10)
outputBuffer.get(rawOutput)
val outParams = interpreter.getOutputTensor(0).quantizationParams()
val outScale = outParams.scale
val outZeroPoint = outParams.zeroPoint
val probabilities = FloatArray(10)
for (i in 0 until 10) {
val uint8 = rawOutput[i].toInt() and 0xFF
probabilities[i] = (uint8 - outZeroPoint) * outScale
}여기서 Softmax를 또 태우면 안 된다. base 모델 마지막 레이어가 이미 softmax라 확률이 그대로 나오니까. 이중 적용하면 argmax 순위는 유지되는데 confidence만 평평해진다. "예측은 맞는데 자신감이 없는" 애매한 버그가 이렇게 생긴다.
모델이 logits를 뱉으면(이번 시리즈의 Teacher/Student 같은) 반대로 이 자리에서 softmax를 꼭 걸어야 한다. 배포 전에 모델 출력이 확률인지 logits인지부터 확인하는 게 먼저다.
실무에서 주의할 점이 하나 있다. OpenCV나 Camera Preview에서 이미지를 가져오면 BGR 순서로 오는 경우가 있다. 모델이 RGB로 학습됐으면 순서를 바꿔야 한다. 안 바꾸면 정확도가 크게 떨어지는데, 원인 찾기가 어렵다.
GPU를 켜면 빨라질까?
당연히 빨라질 거라고 생각했다. GPU Delegate를 켜봤다.
val compatList = CompatibilityList()
if (compatList.isDelegateSupportedOnThisDevice) {
// INT8 양자화 모델도 GPU에서 돌릴 수 있게 허용
val delegateOptions = GpuDelegate.Options().apply {
setQuantizedModelsAllowed(true)
}
val gpuDelegate = GpuDelegate(delegateOptions)
options.addDelegate(gpuDelegate)
}INT8 모델은 GPU에서 돌릴 때 setQuantizedModelsAllowed(true)를 켜줘야 한다. GPU가 INT8 연산을 네이티브로 지원하지 않으면 이 옵션이 내부적으로 dequantize → FP 연산 → quantize 과정을 처리해준다.
Galaxy S22+에서 측정한 결과:
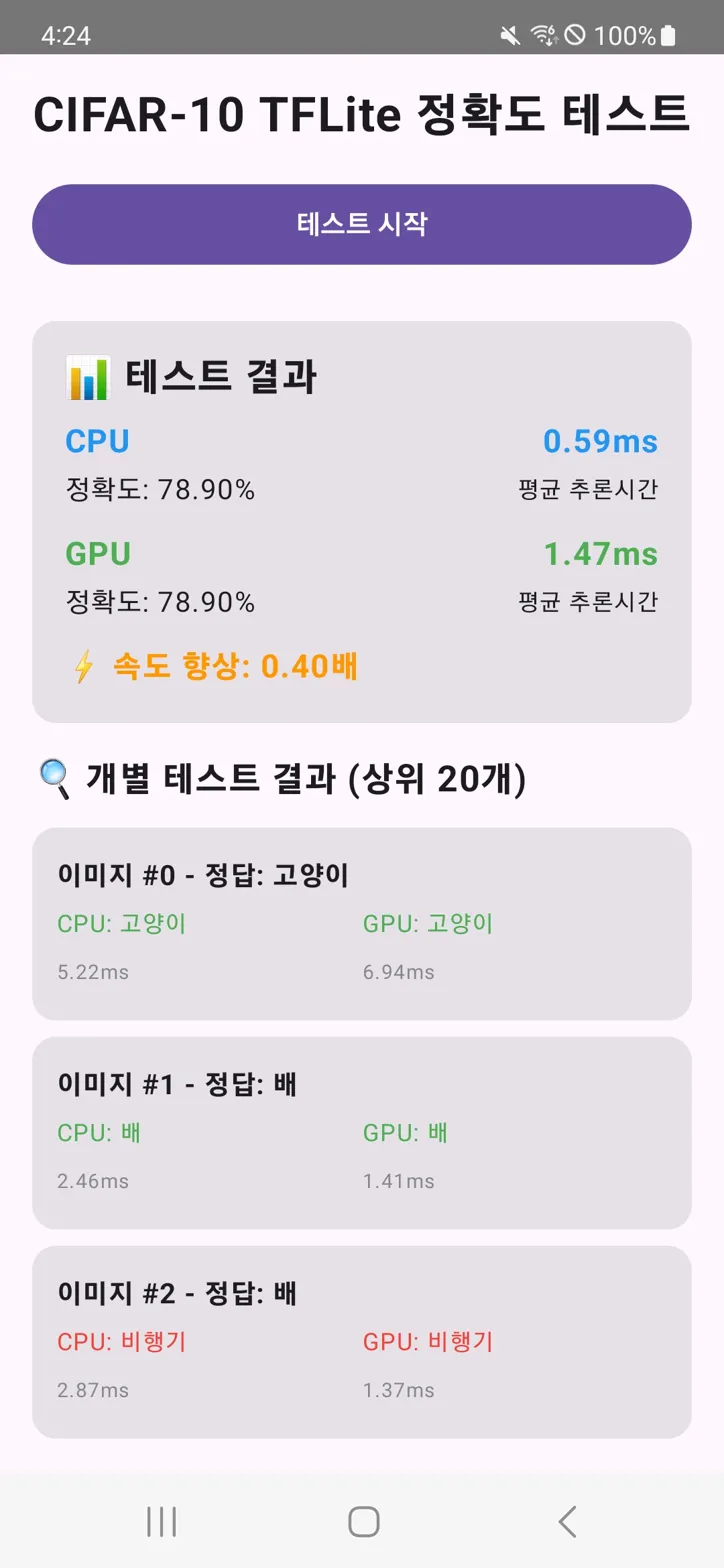
CPU: 0.59ms
GPU: 1.47msGPU가 2.5배 느렸다. 직관과 반대다.
이해가 안 돼서 회사 AI 전문가 동료한테 물어봤다. 답은 단순했다. CPU에서 GPU로 입출력 텐서를 복사하는 오버헤드가 있는데, 모델 연산이 0.59ms밖에 안 걸리면 이 전송 비용이 연산보다 커진다. 거기에 INT8 → FP 변환 비용까지 얹히니까 양자화 모델인데 양자화가 발목을 잡는 그림이 된다. 작은 모델에서는 GPU 연산마다 붙는 kernel launch 오버헤드도 무시 못 한다. 연산 자체가 0.59ms짜리면 이 고정 비용의 비중이 확 커진다.
모델이 크면 얘기가 달라진다. 연산량이 전송 오버헤드를 압도하면 GPU가 이긴다. 작은 모델에선 CPU가 이긴다. 모델이 커져서 연산량이 전송 비용을 넘기 시작하면 GPU가 이긴다. "GPU 켜면 빨라진다"가 보편 법칙이 아니라는 건 이번에 수치로 확인했다.
Python vs Android 정확도 비교
경량화한 모델을 Android에 올렸으면, Python에서 나온 정확도가 그대로 나오는지 확인해야 한다. Android용으로 CIFAR-10 test set 앞 1000장을 바이너리로 만들어서 Python과 Android 양쪽에서 돌려봤다.
Python: 78.90%
Android: 78.90%차이 0%p. 같은 .tflite에 전처리와 후처리가 양쪽에서 동일하게 구현됐다는 뜻이다. 1편에서 본 77.88%와 숫자가 다른 건 샘플 수 차이(10000장 전체 vs 앞 1000장)고, 1000장 기준 95% 신뢰구간(76.37% ~ 81.43%) 안에 들어온다. 중요한 건 절대값이 아니라 Python과 Android가 같은 데이터에서 같은 결과를 내는지다.
정확도가 벌어지면 정규화 방식(양자화 스케일, RGB 순서)과 후처리(Softmax 유무)가 일치하는지부터 본다.
추론 속도
Python CPU (Mac): 0.17ms
Android CPU (S22+): 0.59msPython이 3.5배 빠르다. Mac 데스크톱 CPU가 모바일 AP보다 빠른 게 당연하니까 이게 정상이다. 사실 속도 자체보다 중요한 건 "모바일에서 서브밀리초로 돌아간다"는 점이다. 0.59ms면 초당 1700번 추론이 가능하니까, 실시간 UI에 전혀 문제가 없다.
모델 배포
모델을 앱에 넣는 방법은 간단하다. APK에 내장하면 된다. assets/ 폴더에 .tflite 파일을 넣으면 끝이다.
다만 이 방식은 모델을 업데이트할 때마다 앱 전체를 재배포해야 한다. 실서비스에서는 모델 버전 관리와 서빙 파이프라인이 필요한데, 그 부분은 MLflow로 작은 MLOps 파이프라인 만들어보기에서 다뤘다.
다시 보는 온디바이스
세 편을 쓰고 나서야 보이는 게 있다. 시작할 때는 경량화가 문제인 줄 알았다. 양자화/프루닝/증류 중 뭘 쓸지 고르는 게 핵심이라고 생각했다. 끝내고 보니 아니었다.
돌아보면 경량화 기법 고르기는 진짜 문제가 아니었다. 문제는 연산량이랑 오버헤드 중에 뭐가 더 큰지를 먼저 봤어야 하는 거였다.
2편에서 프루닝한 모델은 계산량을 반으로 줄이고도 1.4배 느려졌다. 3편에서 GPU는 CPU보다 2.5배 느렸다. 두 결과의 원인이 같다. 연산 자체가 169μs / 0.59ms 수준으로 이미 충분히 작으니까, sparse 분기 오버헤드와 GPU 텐서 전송 비용이 연산을 넘어선다. 크기를 줄이는 데는 성공했는데 줄어든 연산보다 붙는 오버헤드가 더 비싼 지점에 모델이 도달해버린 거다.
그래서 "경량화 기법 뭐 쓸까"보다 먼저 던져야 할 질문이 있다. 지금 병목이 연산인가, 아닌가.
연산이 병목이면 교과서 순서대로 가면 된다. INT8 양자화로 시작, 부족하면 증류, 프루닝은 하드웨어가 받쳐줄 때만. GPU도 켜는 게 이득이다.
문제는 병목이 연산이 아닐 때다. 이번 실험처럼 모델이 이미 서브밀리초로 도는 상황이면, 경량화를 더 하는 게 오히려 역효과를 낸다. GPU도 꺼두는 편이 빠르다. "GPU 먼저 켜자"가 보편 법칙이 아닌 이유다.
이 질문을 미리 못 던진 게 작년에 온디바이스를 어렵게 느낀 이유였다. 경량화는 공짜에 가까웠다. 어려웠던 건 모델 크기와 하드웨어 사이 어디에 병목이 있는지 감을 잡는 일이었다.
다시 만든다면 순서를 바꿀 것 같다. 경량화 기법을 전부 걸어보기 전에 INT8 양자화만 먼저 하고 타깃 디바이스에서 돌려본다. 거기서 연산이 병목이라고 확인되면 그때 구조를 건드린다. 아니면 그대로 출고한다. 이 사이클이 2~3일짜리라 "우선 다 해보고 최적 조합 찾자"보다 훨씬 싸다.
Gemma 4 E2B 같은 경량 모델이 나오고 TurboQuant 같은 압축 기술이 발표되는 지금, 모델 쪽 여유는 점점 넓어진다. 그만큼 병목도 연산에서 메모리/전송으로 옮겨간다. 결국 이 블로그 시리즈의 결론은 기법 순서가 아니라 병목을 먼저 측정하자다.
다음에 보이스피싱 탐지 KoBERT를 다시 집어 든다면 시작점은 정해져 있다. DistilKoBERT + INT8을 타깃 단말에 올리고, 거기서 병목을 본다.
소스 코드
https://github.com/yjcho9317/CIFAR10_OnDevice
참고 자료
- LiteRT (TensorFlow Lite) Documentation: https://www.tensorflow.org/lite
- ExecuTorch Documentation: https://pytorch.org/executorch/stable/index.html
- ONNX Runtime Documentation: https://onnxruntime.ai/docs/
- Android Developers - ML Kit Documentation: https://developers.google.com/ml-kit
'AI' 카테고리의 다른 글
| 온디바이스 AI 경량화 (2) — 프루닝과 지식 증류 실전 비교 (AGP, Temperature, KL Divergence) (0) | 2026.04.17 |
|---|---|
| 온디바이스 AI 경량화 (1) — INT8 양자화로 CIFAR-10 모델 92% 줄이기 (TFLite PTQ) (0) | 2026.04.17 |
| MLOps 구축기 (5) - MLflow 기반 MLOps 파이프라인 전체 정리 (1) | 2026.03.13 |
| MLOps 구축기 (4) - GitHub Actions CI/CD와 Prometheus + Grafana 모니터링 (0) | 2026.03.13 |
| MLOps 구축기 (3) - MLflow 모델을 FastAPI로 서빙하기 (0) | 2026.03.08 |