
4편에 걸쳐 MLOps 환경을 처음부터 만들어봤다.
- MLflow 실험 추적
- 모델 레지스트리
- FastAPI 서빙
- GitHub Actions CI/CD
- Prometheus + Grafana 모니터링
결과적으로 docker compose up -d 한 번으로 전체 환경이 올라오는 구조가 됐다.
이번 글에서는 코드나 설정을 더 추가하지 않는다.
대신 이 구조가 왜 이렇게 만들어졌는지, 그리고 실무에서는 어디까지 확장되는지를 정리해보려고 한다.
전체 아키텍처
지금까지 만든 구조를 한 번에 보면 이렇다.
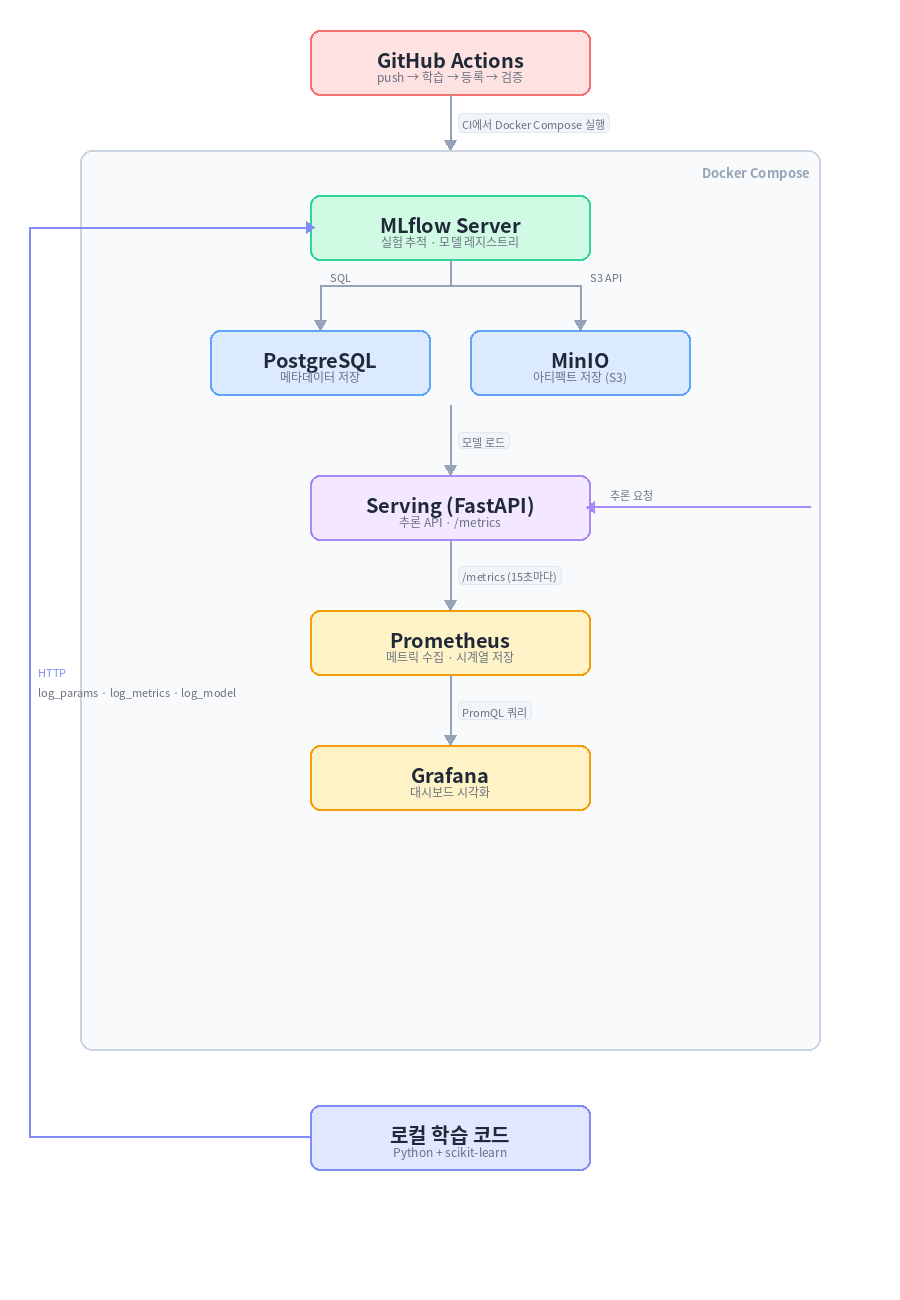
처음 보면 복잡해 보이지만, 실제로는 역할이 명확하게 나뉜 구조다.
왜 이런 구조가 되는가
MLOps 시스템은 대부분 다음 네 가지 문제를 해결하려고 만든다.
모델 학습 관리
모델 저장
모델 배포
운영 모니터링지금 만든 구조도 결국 이 네 가지 역할로 나뉜다.
| 역할 | 구성 |
|---|---|
| 실험 관리 | MLflow |
| 모델 저장 | MinIO |
| 메타데이터 | PostgreSQL |
| 서빙 | FastAPI |
| 모니터링 | Prometheus + Grafana |
| 자동화 | GitHub Actions |
각 도구는 하나의 문제만 해결한다.
이게 중요한 이유는 나중에 교체가 가능하기 때문이다.
예를 들어 다음처럼 바꿀 수 있다.
MinIO → AWS S3
FastAPI → KServe
Docker Compose → Kubernetes구조가 분리되어 있으면 이런 변경이 훨씬 쉽다.
이 구조가 MLOps의 최소 단위다
여기까지 만들면 보통 이런 질문이 나온다.
“이 정도면 실제 MLOps 환경이라고 볼 수 있을까?”
대부분의 경우 그렇다.
많은 MLOps 플랫폼도 결국 같은 구조를 가진다.
학습
→ 실험 기록
→ 모델 저장
→ 모델 서빙
→ 모니터링차이는 규모와 자동화 수준이다.
예를 들어
| 개인 프로젝트 | 대규모 서비스 |
|---|---|
| Docker Compose | Kubernetes |
| MinIO | AWS S3 |
| FastAPI | KServe / BentoML |
| 수동 학습 | 파이프라인 오케스트레이션 |
하지만 기본 흐름은 크게 다르지 않다.
컴포넌트 간 통신 흐름
구조를 이해하려면 데이터 흐름을 보는 게 가장 쉽다.
학습 과정
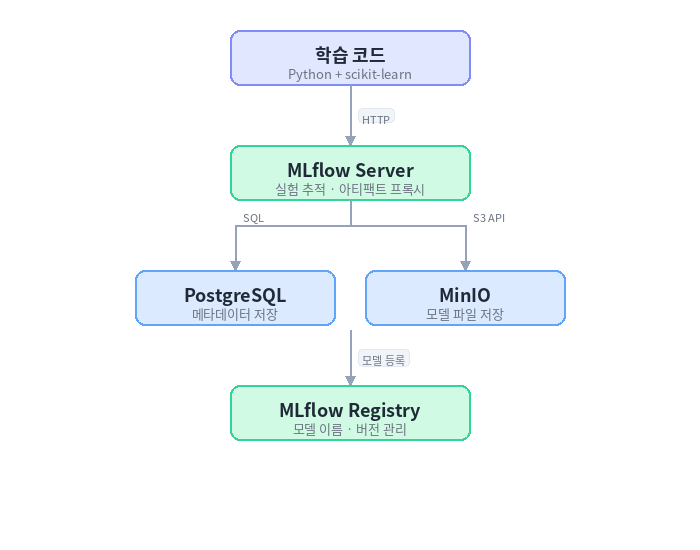
학습 코드는 MLflow에 실험 결과를 기록하고, 모델 파일은 MinIO에 저장된다.
서빙 과정
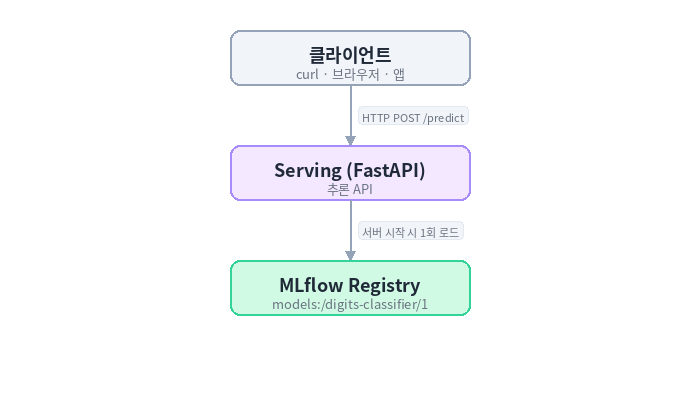
서빙 서버는 시작할 때 모델을 한 번만 불러온다.
요청이 들어올 때마다 모델을 다시 로드하지 않기 때문에 성능이 안정적이다.
모니터링 과정
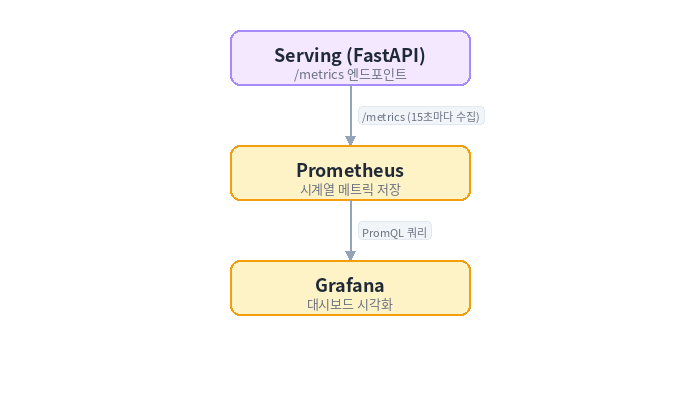
Prometheus는 숫자 메트릭만 저장한다.
예를 들어
- 요청 수
- 에러율
- 응답 시간
같은 데이터다.
로그 분석과는 목적이 다르다.
실무에서는 무엇이 더 추가될까
지금 만든 구조는 기본 골격이다.
실제 환경에서는 여기에 몇 가지 기능이 더 붙는다.
데이터 버전 관리
모델을 재현하려면 데이터 버전이 필요하다.
코드는 Git으로 관리하지만 데이터는 그렇지 않다.
그래서 보통
DVC 같은 도구를 사용한다.
데이터셋이 고정된 프로젝트에서는 큰 문제가 없지만
데이터가 계속 추가되는 시스템에서는 필수에 가깝다.
A/B 테스트
새 모델을 바로 전체 트래픽에 적용하는 건 위험하다.
그래서 보통 이렇게 배포한다.
기존 모델 → 90%
새 모델 → 10%성능이 검증되면 트래픽을 점점 늘린다.
이건 보통 API 게이트웨이나 서비스 메시에서 처리한다.
데이터 드리프트 감지
시간이 지나면 데이터 분포가 바뀐다.
예를 들어
- 추천 시스템
- 이상 탐지
- 사기 탐지
같은 모델은 입력 데이터가 계속 변한다.
그래서 데이터 분포 변화를 감지하고 재학습을 트리거하는 시스템을 붙이기도 한다.
Feature Store
학습과 서빙에서 같은 feature를 사용하도록 보장하는 시스템이다.
학습과 서빙 로직이 달라지면 training-serving skew 문제가 생긴다.
이걸 해결하기 위해 Feature Store를 사용한다.
대표적인 도구는
Feast 가 있다.
이 구조의 한계
여기까지 만들면 꽤 완성된 것처럼 보인다.
하지만 몇 가지 한계도 있다.
1. 대규모 트래픽
FastAPI 단일 서버로는 대규모 트래픽을 처리하기 어렵다.
이 경우
로드 밸런서
+ 여러 서빙 인스턴스구조로 확장해야 한다.
2. GPU 서빙
딥러닝 모델은 GPU가 필요할 수 있다.
이 경우
Kubernetes
+ GPU scheduling환경이 필요하다.
3. 모델 수 증가
모델이 많아지면 관리가 복잡해진다.
이때는 보통
모델 서빙 플랫폼을 따로 사용한다.
예를 들어
- KServe
- BentoML
같은 도구다.
왜 여기서 멈췄는가
이 시리즈는 MLOps의 핵심 구조를 이해하는 것을 목표로 했다.
여기서 더 나아가려면 다음이 필요하다.
- 실제 데이터 파이프라인
- 실제 트래픽
- 장기 운영 환경
이런 요소가 없으면 실습으로 만들기 어렵다.
그래서 이번 시리즈는 핵심 골격까지 만드는 데서 멈췄다.
시리즈 요약
| 편 | 내용 |
|---|---|
| 1편 | MLflow 실험 추적 환경 구축 |
| 2편 | 실험 비교와 모델 레지스트리 |
| 3편 | FastAPI 모델 서빙 |
| 4편 | CI/CD와 모니터링 |
| 5편 | 전체 구조 정리 |
마무리
직접 MLOps 환경을 만들어보면서 느낀 건 하나다.
MLOps는 복잡한 시스템처럼 보이지만 결국 역할 분리 문제라는 것.
학습
→ 기록
→ 저장
→ 서빙
→ 모니터링이 다섯 가지를 어떻게 분리하느냐가 핵심이다.
지금 만든 구조는 아주 작은 규모지만,
대부분의 MLOps 플랫폼도 같은 흐름 위에서 동작한다.
그래서 이 구조를 이해하고 있으면
더 큰 시스템을 볼 때도 훨씬 빠르게 이해할 수 있다.
'AI' 카테고리의 다른 글
| 온디바이스 AI 경량화 (2) — 프루닝과 지식 증류 실전 비교 (AGP, Temperature, KL Divergence) (0) | 2026.04.17 |
|---|---|
| 온디바이스 AI 경량화 (1) — INT8 양자화로 CIFAR-10 모델 92% 줄이기 (TFLite PTQ) (0) | 2026.04.17 |
| MLOps 구축기 (4) - GitHub Actions CI/CD와 Prometheus + Grafana 모니터링 (0) | 2026.03.13 |
| MLOps 구축기 (3) - MLflow 모델을 FastAPI로 서빙하기 (0) | 2026.03.08 |
| MLOps 구축기 (2) - MLflow 하이퍼파라미터 실험 관리와 Model Registry (0) | 2026.03.08 |