
1편에서 Docker Compose로 MLflow 실험 추적 서버를 만들었다.
모델을 학습하면서 파라미터, 메트릭, 모델 파일을 자동으로 기록하는 것까지 확인했다.
하지만 실험을 한 번만 돌려서는 MLflow를 쓸 이유가 없다.
MLflow가 진짜 유용해지는 순간은
실험을 여러 번 돌리고 비교할 때다.
이번 글에서는 하이퍼파라미터를 바꿔가며 여러 번 학습하고, MLflow UI에서 성능을 비교한 뒤, 가장 좋은 모델을 레지스트리에 등록하고, 코드에서 불러와 추론하는 과정을 다룬다.
같은 모델인데 성능이 왜 이렇게 다를까
머신러닝 모델은 파라미터 설정에 따라 성능이 크게 달라진다.
예를 들어 RandomForest에서 n_estimators = 1과 n_estimators = 200은 완전히 다른 모델이라고 봐도 된다.
실제로 간단히 실험해 보면 이런 결과가 나온다.
n_estimators= 1 → accuracy 0.37
n_estimators=200 → accuracy 0.97같은 알고리즘인데 성능이 60%p 차이 난다.
이런 차이를 찾는 과정이 하이퍼파라미터 튜닝이다.
문제는 여기서 생긴다.
실험이 몇 개 안 될 때는 괜찮다.
하지만 10개, 20개 넘어가면
"어떤 설정이 가장 좋았는지" 기억이 안 난다.
그래서 실험 기록이 필요하다.
실험 코드
1편에서는 Iris 데이터셋을 사용했다.
문제는 Iris가 너무 쉽다는 거다.
웬만한 모델은 거의 accuracy 1.0이 나온다.
그래서 이번에는 digits 데이터셋으로 바꿨다.
손글씨 숫자를 분류하는 데이터셋인데
클래스도 많고 경계가 복잡해서 파라미터에 따라 성능 차이가 잘 드러난다.
# src/train_experiments.py
import mlflow
import mlflow.sklearn
from sklearn.datasets import load_digits
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, f1_score
mlflow.set_tracking_uri("http://localhost:5001")
mlflow.set_experiment("digits-tuning")
X, y = load_digits(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
experiments = [
{"n_estimators": 1, "max_depth": 2},
{"n_estimators": 3, "max_depth": 3},
{"n_estimators": 5, "max_depth": 5},
{"n_estimators": 10, "max_depth": 5},
{"n_estimators": 30, "max_depth": 10},
{"n_estimators": 50, "max_depth": 10},
{"n_estimators": 100, "max_depth": 20},
{"n_estimators": 200, "max_depth": None},
]
for params in experiments:
with mlflow.start_run(
run_name=f"rf_n{params['n_estimators']}_d{params['max_depth']}"
):
model = RandomForestClassifier(**params, random_state=42)
model.fit(X_train, y_train)
preds = model.predict(X_test)
acc = accuracy_score(y_test, preds)
f1 = f1_score(y_test, preds, average="weighted")
mlflow.log_params(params)
mlflow.log_metrics({
"accuracy": acc,
"f1_score": f1
})
mlflow.sklearn.log_model(model, "model")
print(
f"n_estimators={params['n_estimators']:>3}, "
f"max_depth={str(params['max_depth']):>4} "
f"→ acc={acc:.4f}, f1={f1:.4f}"
)여기서 핵심은 두 가지다.
파라미터 조합 리스트
experiments = [...]실험할 파라미터를 리스트로 정의한다.
run 단위 기록
with mlflow.start_run():반복문 안에서 run을 시작하면
각 실험이 MLflow에 개별 run으로 기록된다.
실험 실행
python src/train_experiments.py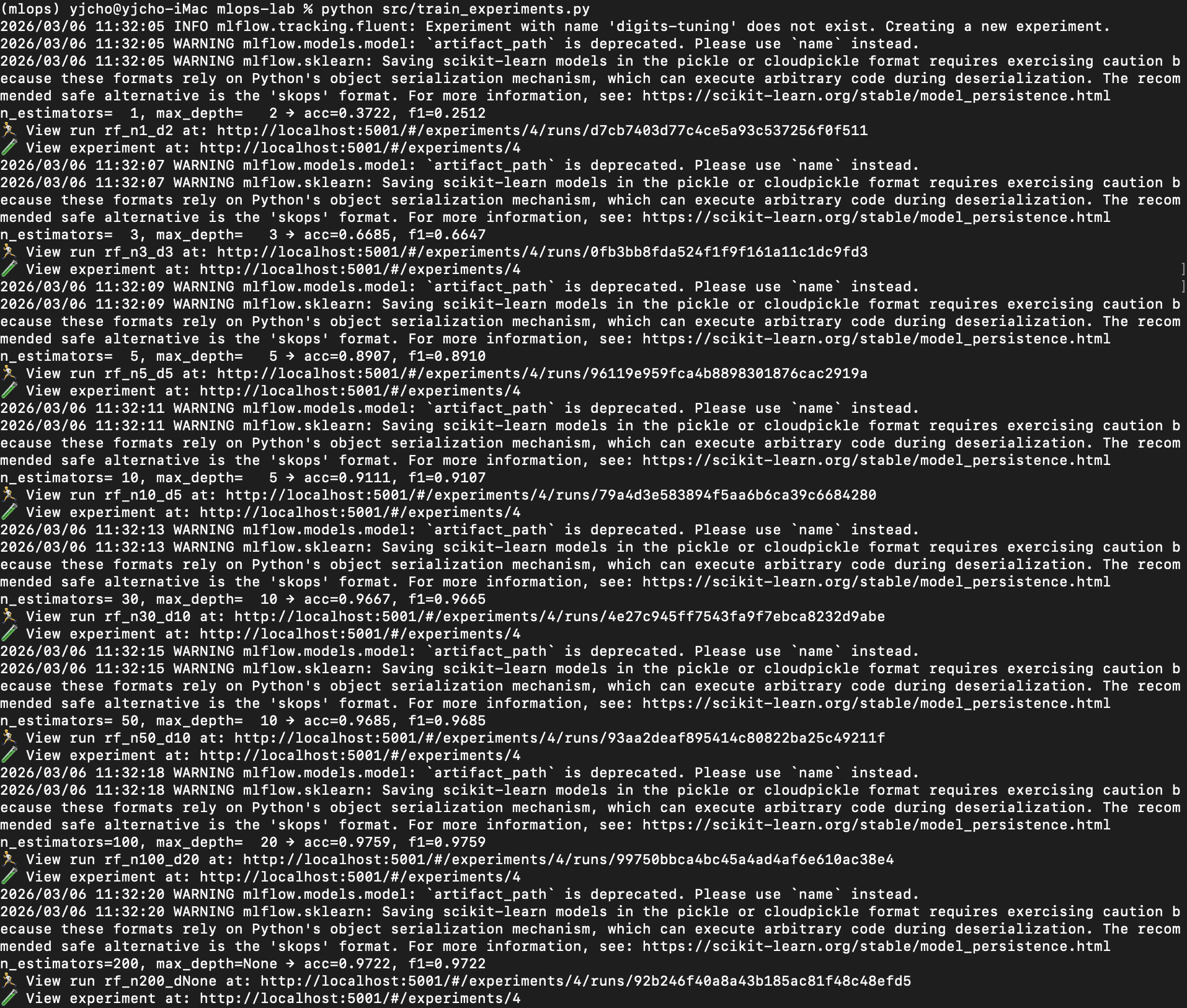
실행하면 이런 결과가 나온다.
n_estimators= 1, max_depth= 2 → acc=0.3704, f1=0.2533
n_estimators= 3, max_depth= 3 → acc=0.6704, f1=0.6589
n_estimators= 5, max_depth= 5 → acc=0.8889, f1=0.8876
n_estimators= 10, max_depth= 5 → acc=0.9111, f1=0.9105
n_estimators= 30, max_depth= 10 → acc=0.9685, f1=0.9684
n_estimators= 50, max_depth= 10 → acc=0.9704, f1=0.9703
n_estimators=100, max_depth= 20 → acc=0.9759, f1=0.9759
n_estimators=200, max_depth=None → acc=0.9741, f1=0.9739트리 1개짜리는 정확도 0.37
트리 100개짜리는 0.976
같은 RandomForest인데 성능 차이가 엄청 크다.
재미있는 점도 하나 있다.
n_estimators=100 → 0.9759
n_estimators=200 → 0.9741트리를 더 많이 썼는데
성능이 오히려 조금 떨어졌다.
이런 걸 직접 확인하려면
실험 기록과 비교가 필요하다.
MLflow UI에서 비교하기
브라우저에서 MLflow UI에 접속한다.
http://localhost:5001digits-tuning 실험에 들어가면
방금 실행한 8개의 run이 보인다.
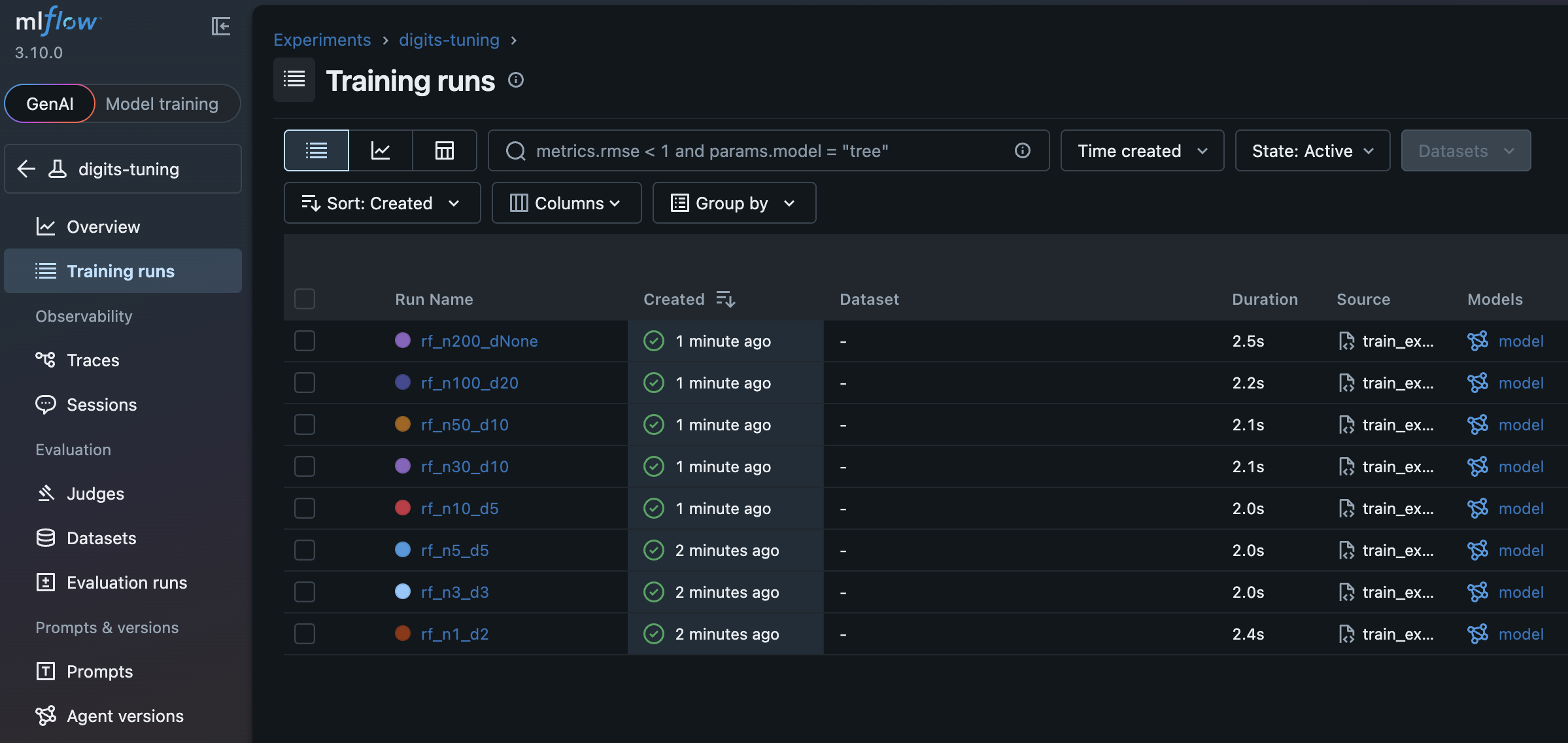
Overview 탭에서 차트를 보면
accuracy가 어떻게 올라가는지 한눈에 확인된다.
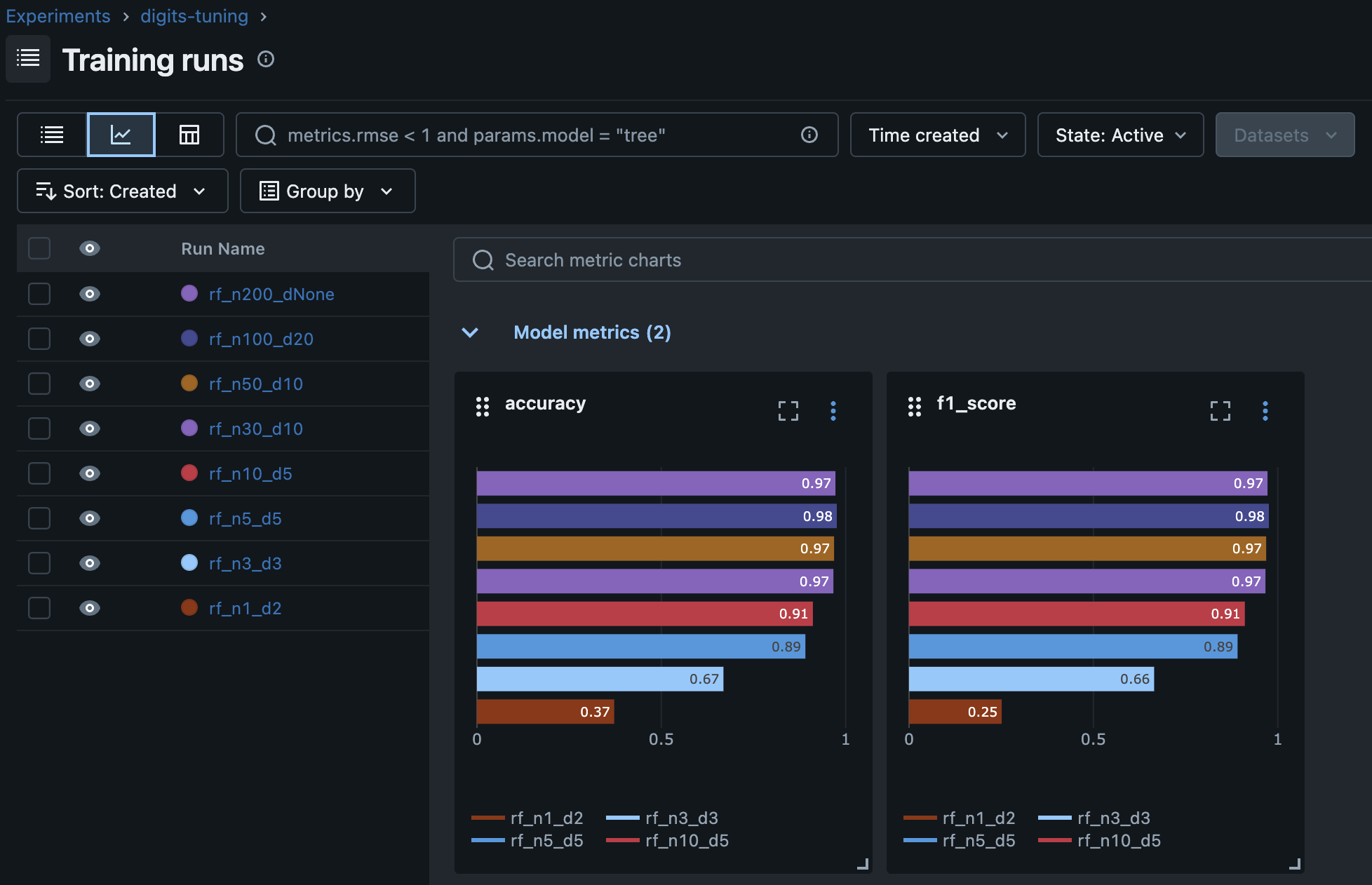
이게 MLflow를 쓰는 이유다.
실험을 여러 번 돌려도 기록은 자동이고, 비교는 UI에서 바로 할 수 있다. 수동으로 관리했다면 엑셀 정리부터 해야 했을 거다.
최적 모델 레지스트리 등록
이제 가장 성능이 좋은 모델을 등록한다.
MLflow에는 Model Registry라는 기능이 있다.
"실제로 사용할 모델"을
버전 단위로 관리하는 저장소다.
# src/register_best_model.py
import mlflow
from mlflow import MlflowClient
mlflow.set_tracking_uri("http://localhost:5001")
client = MlflowClient()
experiment = client.get_experiment_by_name("digits-tuning")
best_run = client.search_runs(
experiment_ids=[experiment.experiment_id],
order_by=["metrics.accuracy DESC"],
max_results=1
)[0]
print(f"Best run: {best_run.info.run_name}")
print(f" accuracy: {best_run.data.metrics['accuracy']:.4f}")
print(f" f1_score: {best_run.data.metrics['f1_score']:.4f}")
print(f" run_id: {best_run.info.run_id}")
model_uri = f"runs:/{best_run.info.run_id}/model"
result = mlflow.register_model(
model_uri,
"digits-classifier"
)
print(f"\nModel registered!")
print(f" Name: {result.name}")
print(f" Version: {result.version}")핵심은 이 부분이다.
order_by=["metrics.accuracy DESC"]accuracy 기준으로 정렬해서
가장 좋은 run 하나를 찾는다.
그 다음 레지스트리에 등록한다.
나중에 모델을 개선해서 다시 등록하면 Version 2, 3으로 올라간다. 어떤 버전이 언제, 어떤 실험에서 나왔는지 추적이 된다.
python src/register_best_model.py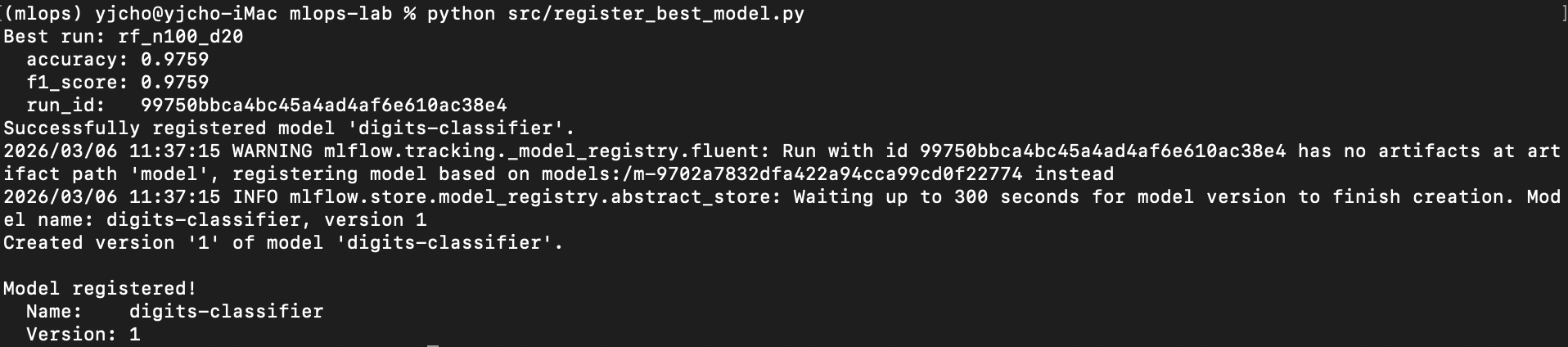
Best run: rf_n100_d20
accuracy: 0.9759
f1_score: 0.9759
Model registered!
Name: digits-classifier
Version: 1모델 등록이 완료됐다고 나오고, MLflow로 가보면 Model registry에 모델이 등록된걸 볼 수 있다.
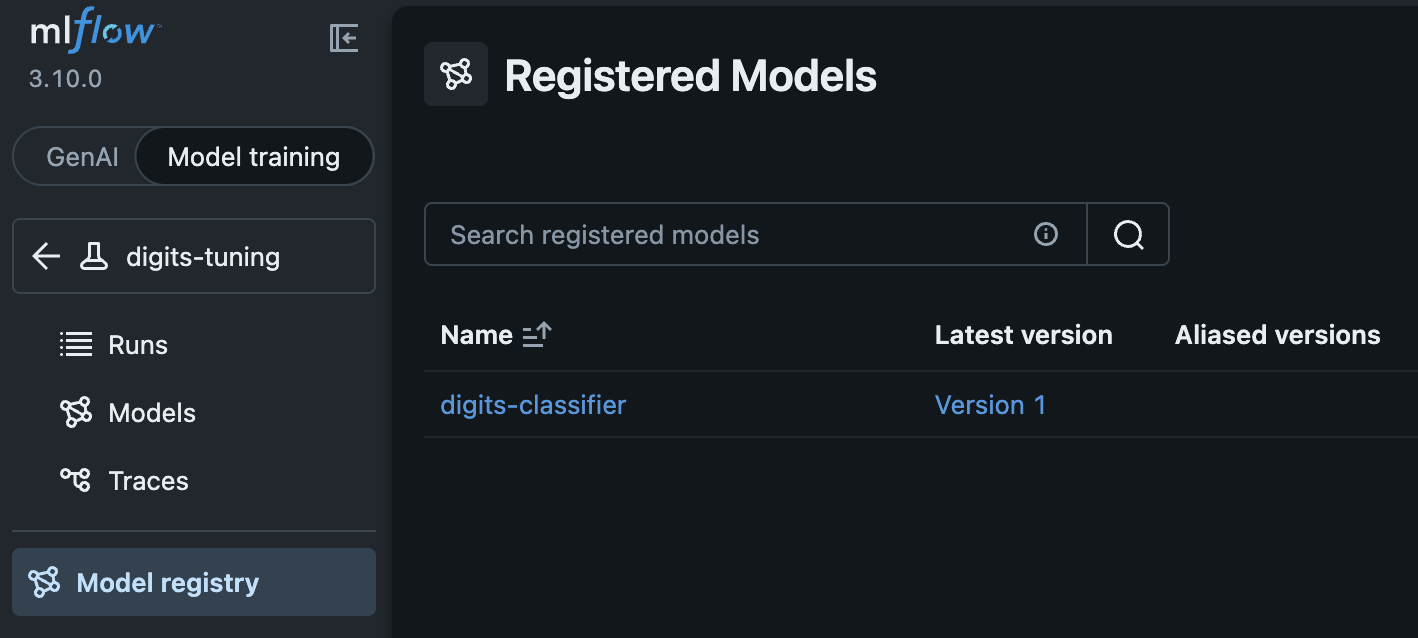
MLflow에서 Models로 이동하면 8개의 run 중 어느 run이 등록 됐는지 표시도 되어있다.
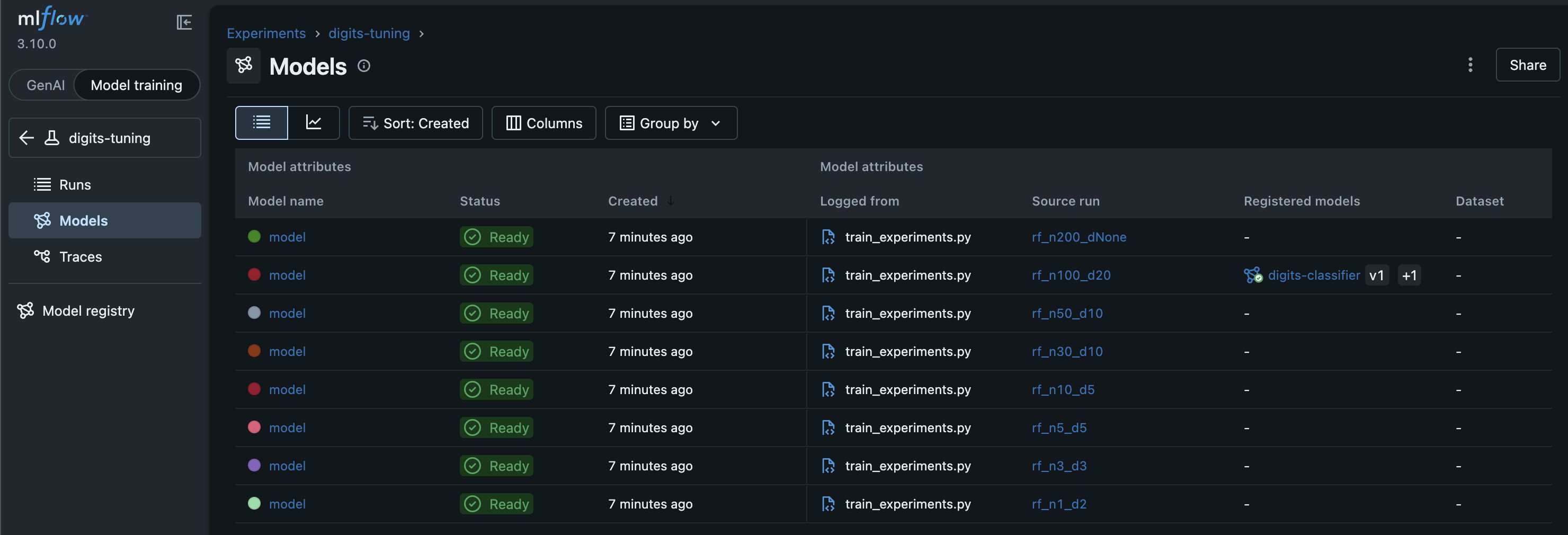
등록된 모델로 추론
이제 레지스트리에서 모델을 불러와서 추론해본다. 실제로 모델을 배포할 때도 이 방식으로 레지스트리에서 특정 버전을 꺼내 쓴다.
# src/predict.py
import mlflow
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
mlflow.set_tracking_uri("http://localhost:5001")
model = mlflow.sklearn.load_model("models:/digits-classifier/1")
X, y = load_digits(return_X_y=True)
_, X_test, _, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
preds = model.predict(X_test)
print("예측 | 정답")
print("-----------")
for i in range(5):
mark = "O" if preds[i] == y_test[i] else "X"
print(f" {preds[i]} | {y_test[i]} {mark}")
print(f"\n전체 정확도: {accuracy_score(y_test, preds):.4f}")중요한 점은 모델 파일 경로를 직접 지정하지 않는다는 것이다.
레지스트리 이름과 버전만 알면 MLflow가 알아서 모델 위치를 찾는다. MinIO에 저장됐든 S3에 저장됐든 코드는 바뀌지 않는다.
python src/predict.py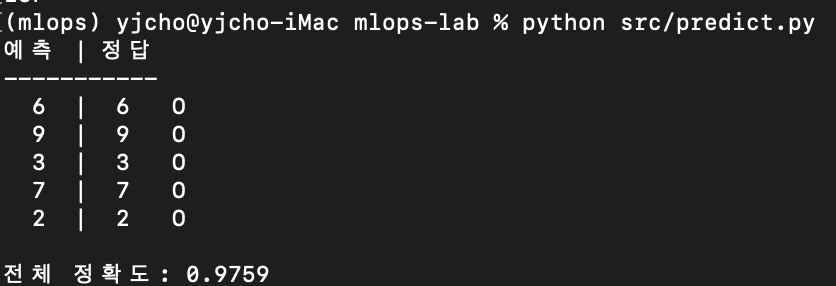
예측 | 정답
-----------
6 | 6 O
9 | 9 O
3 | 3 O
7 | 7 O
2 | 2 O
전체 정확도: 0.9759등록할 때의 accuracy 0.9759와 추론 결과가 일치한다. 레지스트리에서 꺼낸 모델이 학습 시점과 동일하게 동작하는 거다.
정리
이번 글에서 한 과정을 정리하면 이렇다.
파라미터 정의
→ 여러 번 학습
→ MLflow에 자동 기록
→ UI에서 성능 비교
→ 최적 모델 선택
→ 레지스트리 등록
→ 코드에서 로드
→ 추론 검증이 흐름이 MLflow의 기본 사이클이다.
실험이 10개든 1000개든
같은 방식으로 관리할 수 있다.
다음 편에서는
이 모델을 FastAPI로 서빙하는 과정을 정리해볼 예정이다.
사용한 도구
- MLflow 3.10.0 (실험 추적 + 모델 레지스트리)
- scikit-learn (RandomForest, digits 데이터셋)
- Docker Compose (1편에서 구축한 인프라)
'AI' 카테고리의 다른 글
| 온디바이스 AI 경량화 (1) — INT8 양자화로 CIFAR-10 모델 92% 줄이기 (TFLite PTQ) (0) | 2026.04.17 |
|---|---|
| MLOps 구축기 (5) - MLflow 기반 MLOps 파이프라인 전체 정리 (1) | 2026.03.13 |
| MLOps 구축기 (4) - GitHub Actions CI/CD와 Prometheus + Grafana 모니터링 (0) | 2026.03.13 |
| MLOps 구축기 (3) - MLflow 모델을 FastAPI로 서빙하기 (0) | 2026.03.08 |
| MLOps 구축기 (1) - MLflow Tracking Server 구축 (Docker Compose + PostgreSQL + MinIO) (0) | 2026.03.05 |